CSIRO Computing History: Sidebar 1: The start of on-line data, and the management of shared storage
Last updated: 8 Dec 2020.
Robert C. Bell
Status: Complete with content from Chapters 2 and 3.
Started adding more about the management of shared storage.
previous chapter — contents — next chapter
The start of on-line data
(See also Chapters 2 and 3 of this history for the wider context.)
Trevor Pearcey in his 1948 paper “Modern Trends in Machine Computation” wrote:

This clearly envisaged a means to store information digitally.
In 1962, a proposal from Trevor Pearcey with the support of E.A. Cornish from DMS for the establishment of a ‘network’ of computing facilities was approved by the CSIRO Executive, and received government funding. CSIRO established a Computing Research Section on 1 January 1963.
The contracts for the equipment and building were announced in CoResearch in July 1963 – see CoResearch no. 52 July 1963 .
CSIRO established a service in 1964 based on a CDC 3600 on Black Mountain in Canberra, and CDC 3200s in Melbourne, Sydney and Adelaide.
The original plan was for the CDC 3600 in Canberra, and four subsidiary machines, one in Canberra to handle input and output, and one each in Adelaide, Melbourne and Sydney – see The scientific computing network 1. The Central Laboratory – CSIRO Computing Research Section, October 1963.
Section 4. Auxiliary equipment included the following:

The plan was amended to drop the Canberra 3200, and to add to the 3600 a drum rather than the initially-envisaged disc storage, and to add visual displays, with Memoranda 1 and 2 dropped and replaced by Memorandum 4. Later, a disc store was added as well.
The scientific computing network 4. Revised equipment configurations – T.S.Holden, 31.7.64.
The list below gives an idea of what constituted a computing system in 1964. Note the memory sizes, and the size of the drum to come. Until that arrived, all the software was on tape: the compiler, the loader, the software libraries, etc.

Since a word on the 3600 was 48 bits (8 DISPLAY-code 6-bit characters, or six 8-bit bytes), total memory capacity was 32768 x 6 = 196608 bytes and the drum capacity was 4 x 5e5 x 6 = 12 Mbytes.
Here are some of the changes from the initial proposal:


The drum access time of 17 ms is comparable to today’s disc drives – e.g. “Average seek time ranges from under 4 ms for high-end server drives, to 15 ms for mobile drives, with the most common mobile drives at about 12 ms and the most common desktop drives typically being around 9 ms.”, to which has to be added rotational delays of 2 to 7 ms (https://en.wikipedia.org/wiki/Hard_disk_drive_performance_characteristics). The transfer rate of 1.5 Mbyte/s seems very high for so long ago, and was 16 times the transfer rate of the fastest tape drive. I think the drum storage had a head for each track, so there was no seek time – only rotational delay.
The drum was the beginning of on-line storage for CSIRO.
The Annual report to June 1965 in Section 4 described Research:
 Details were then given on the SCOPE operating system then in operation on the 3600 and 3200s. The chief drawback was that it did one task at a time, so, for example, while reading the cards for a job (a slow process), the processor was largely idle, and again the processor was largely idle when printing the results from a job. DAD aimed to buffer all the slow input/output, using the drum, and so provide far higher throughput.
Details were then given on the SCOPE operating system then in operation on the 3600 and 3200s. The chief drawback was that it did one task at a time, so, for example, while reading the cards for a job (a slow process), the processor was largely idle, and again the processor was largely idle when printing the results from a job. DAD aimed to buffer all the slow input/output, using the drum, and so provide far higher throughput.
C.S.I.R.O. Computing Research Section – Newsletter No. 8 – 1/1/66 (I’m sure it wasn’t really published on this date!)
Here is the beginning of the building of a library of code – apps these days. They had to be stored on tape, but this reduced the use of cards. The 3200s had no mass storage, though the Monash one did when I used it from 1968 onwards.
C.S.I.R.O. Computing Research Section – Newsletter No. 9 – 1/2/66

This is further evidence of the trend to use magnetic storage rather than cards, and to bring the data and programs closer to the system.
C.S.I.R.O. Computing Research Section – Newsletter No. 11 – 1.4.66

Following this was information and a table about the length of tape needed to write a record of 256 words (48 bits each, so 2048 6-bit characters or 1536 8-bit bytes) at various densities (from 3.31″ to 23.74″ including the inter-record gap of 0.75″). The worst case showed only 14% efficiency compared with the best usage. Users needed to know about tape hardware, and had to manage their own usage of tapes.

The new hardware had arrived, which would begin the era of on-line digital storage for CSIRO. In those days, a small team could write a monitor (operating system), although I suspect it drew on the code in the CDC SCOPE system with the collaboration of CDA staff.
C.S.I.R.O. Computing Research Section – Newsletter No. 12 – 1.5.66
This was a lightweight newsletter, as there was probably a lot of activity preparing for:


CRS was still working towards a unified network, and the above illustrates a first approach to conditional compilation, using the job-stacking program which would now be called a preprocessor to a language. Maintaining multiple versions of code for different environments is an on-going problem.
C.S.I.R.O. Computing Research Section – Newsletter No. 13 – 1.6.66

DAD had arrived! It was not just the addition of drums and displays, but the introduction of time-sharing!
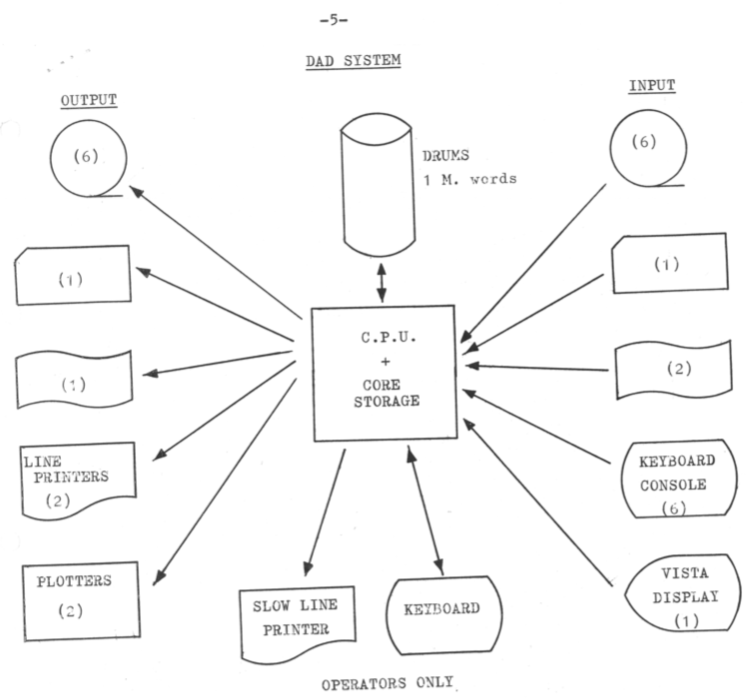
(The unlabelled icons are for cards and paper tape).

Documents became a general term for any stored information. The drum acted as a buffer between input, processing and output, and no doubt greatly added to the throughput.
The queuing system was smart enough to deal with dependencies on data being available, and selected only jobs ready to run. This type of scheduling would still be valuable, and can be achieved with batch systems that cater for file staging. Note that there was a similar splitting of output requests into low and high priority, based on size. Again, crude, but better than no prioritisation, like being stuck in a bank teller queue behind the person lodging the weekend’s school fete takings!

Here is the beginning of two vital concepts – the storing of information in ‘permanent’ on-line digital storage, and interactive access to documents and processing power: both concepts are now so mainstream we barely think about them!
The 1965-1966 Annual Report can be found here.
The drum storage was reported as consisting of two units, rather than the four units proposed earlier.

The Research section highlighted both systems and applications research, particularly the DAD project.
C.S.I.R.O. Computing Research Section – Newsletter No. 14 – 1.7.66

As often happens, two versions of critical software need to be run for some time to allow for conversion. The “DAD Programmers’ Manual”, (Memo No. 5) may be an earlier name for the “THE DAD SYSTEM FOR THE FORTRAN USER” which is accessible below.
The scientific computing network 5. The DAD system for the Fortran user – T. Pearcey, 21.7.66, Edition 1
 The Memorandum no.4 lists four drum units, each with 524,288 48-bit words and each capable of transferring 250,000 words/s. This leads to a total capacity of 12.6 Mbyte and a transfer rate of 6 Mbyte/s, so the whole device could be read or written in a little over 2 seconds! Modern discs take half a day to read or write the entire contents! (12 Tbyte capacity, maximum data rate 245 Mbyte/s https://www.scorptec.com.au/product/Hard-Drives-&-SSDs/HDD-3.5-Drives/73656-WD121PURZ?gclid=EAIaIQobChMI8J_PjbTy4gIVCiUrCh3-owMsEAQYAyABEgIcXPD_BwE).
The Memorandum no.4 lists four drum units, each with 524,288 48-bit words and each capable of transferring 250,000 words/s. This leads to a total capacity of 12.6 Mbyte and a transfer rate of 6 Mbyte/s, so the whole device could be read or written in a little over 2 seconds! Modern discs take half a day to read or write the entire contents! (12 Tbyte capacity, maximum data rate 245 Mbyte/s https://www.scorptec.com.au/product/Hard-Drives-&-SSDs/HDD-3.5-Drives/73656-WD121PURZ?gclid=EAIaIQobChMI8J_PjbTy4gIVCiUrCh3-owMsEAQYAyABEgIcXPD_BwE).
This extract also confirms that system functions under SCOPE were done on the magnetic tapes – e.g. compilers and loaders.

Documents have names, and are record-oriented.

I suspect the i/o caused interrupts, but only to initiate transfers.

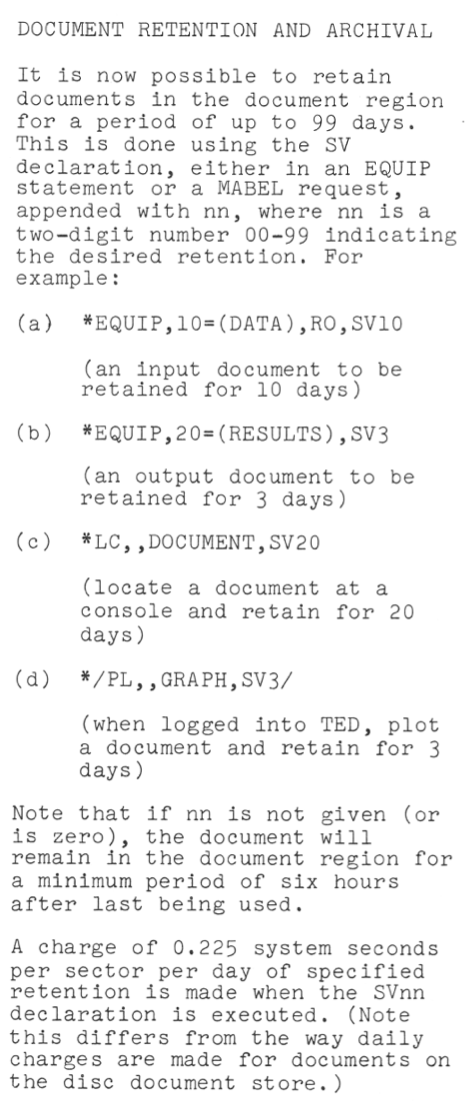
Here is the beginning of the concepts of specifying that documents are to be retained, not just spooled; and a first caution arises about congestion or contention between users for space on a shared storage resource, an un-solved problem for many systems and centres.

Given that the drum was the first random-access permanent storage, it is perhaps not surprising that users were given random access services for the first time. Subroutines had to be called.

Document name restrictions turned out to be very important in the history of computing. Many will be pleased not to remember the DOS restrictions of 8-character names and a 3-character extension.
The notion that only the last 8 characters of any long name would be used turned out to be a bit dangerous. Note that edition numbers were provided, which is an important concept not generally supported in current UNIX/Linux file systems. And, dates and times were attached to the documents, so that they had:
- an owner
- a name (of up to 8 characters)
- a creation date/time
- an edition number
which is not bad for starters.

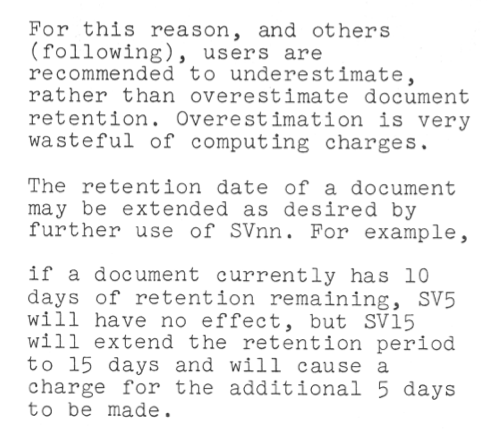
This is a repeated warning about congestion, with the addition of a warning about dropping old documents – flushing in current terminology. It reads like an intention at this stage, rather similar to what many HPC sites currently state but don’t carry out.
C.S.I.R.O. Computing Research Section – Newsletter No. 17 – 1.10.66
The charge of 0.384 seconds per drum sector for storage worked out to be $7.50 per Mbyte. There was no duration on the charge – it was just charged as part of the job for using the space.

There was even a charge for the use of the DELETE command!
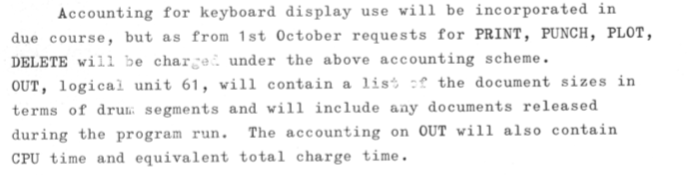
C.S.I.R.O. Computing Research Section – Newsletter No. 19 – 1.12.66
Here is another new concept – ‘output’ being able to be saved and viewed on-line from a console rather than automatically printed and the on-line copy discarded.

(The SCOPE and DAD operating systems used the concept of logical units for i/o, which were core to Fortran. The card reader was on unit 60, and output for printing was on unit 61.)
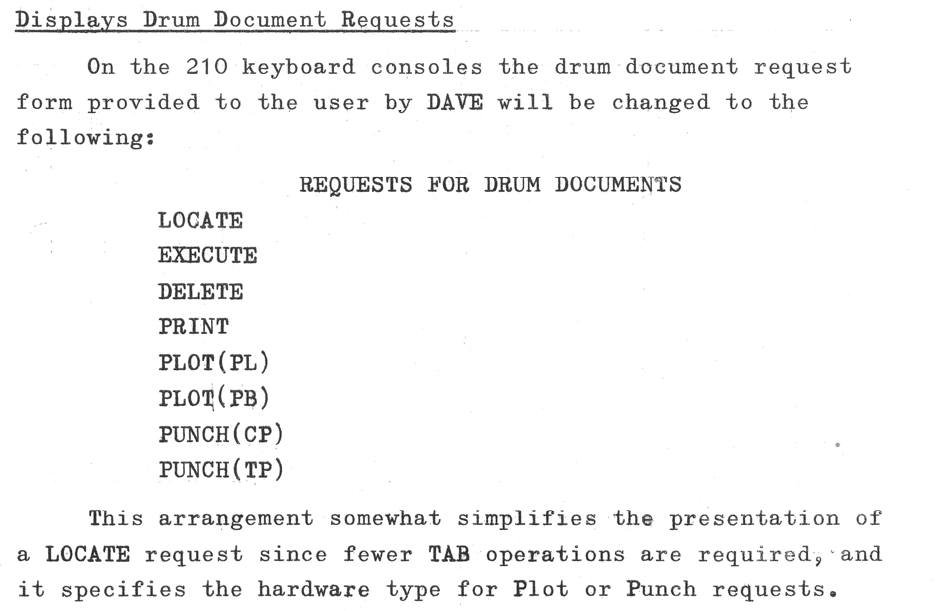
The locate request allowed documents to be found – an audit or listing capability. The display capability was fairly limited in its ability to work with saved documents on the drum, as shown by the commands above, but the CIDER command allowed inspection and editing.
C.S.I.R.O. Computing Research Section – Newsletter No. 21 – 1.3.67
This newsletter announced the first capability in CSIRO for saving data on-line.

Charging was set in advance: $108 per hour for compute, $7.50/Mbyte/day.
The 1966-1967 Annual Report can be found here.
Under the heading Systems Development, the impending arrival of discs at the subsidiaries was noted.

Under the Research section, the further development of DAD to encompass disc storage was outlined.

C.S.I.R.O. Computing Research Section – Newsletter No. 26 – 1.8.67
This newsletter contained an article on the “Storage and Transport of Computer Media”, e.g. punched cards, paper tape.
C.S.I.R.O. Computing Research Section – Newsletter No. 27 – 1.9.67
Increased on-line storage was the big news – discs for the first time. Four million 6-bit characters each for the 3200s, and 100 million 6-bit characters for the 3600.





![]()
Foreshadowed was making available about 10 million characters of space for all the users – not for each!
And, here is the beginning of the FLUSH process for managing a shared region, and the beginning of a Hierarchical Storage Manager, with documents from the drum being copied to magnetic tape and later able to be restored to the drum. This was pioneering work again!



It seems that there was an easy purge process in place – the contents of the drum were lost overnight!
C.S.I.R.O. Division of Computing Research – Newsletter No. 28 – 1.10.1967


Clearly, there were difficulties in managing such a small space in the face of high demand.
Disc access became available on the 3200s:


Note the small size of the disc area available, and the need to take into account blocking, and that discs had gaps, like tape, between blocks of data.
C.S.I.R.O. Division of Computing Research – Newsletter No. 32 – 1.3.1968
“The disc in question (CDC813) consisted of 2 stacks of 18 platters about 600mm in diameter. 64 of the platter surfaces were used for storage totalling 100 million 6-bit characters. Every weekend it was buffed and polished by CDC engineering staff in readiness for the next week. The disc occupied a box about 1800L X 900W X1700H with a separate box of electronics.


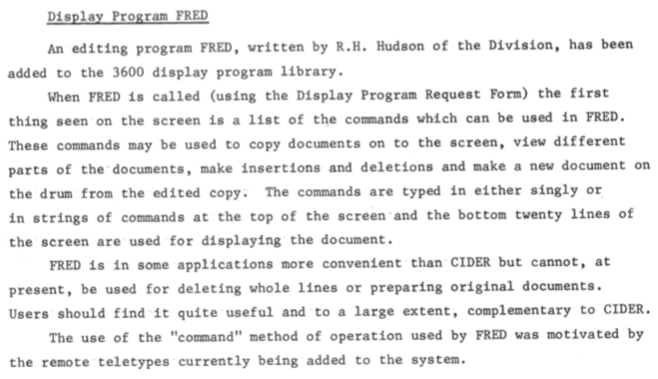
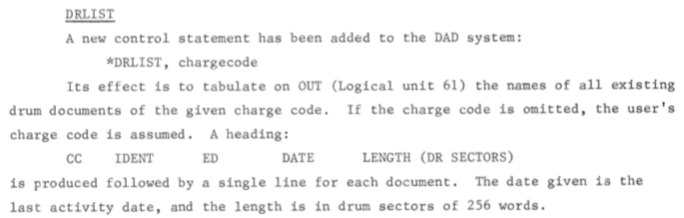


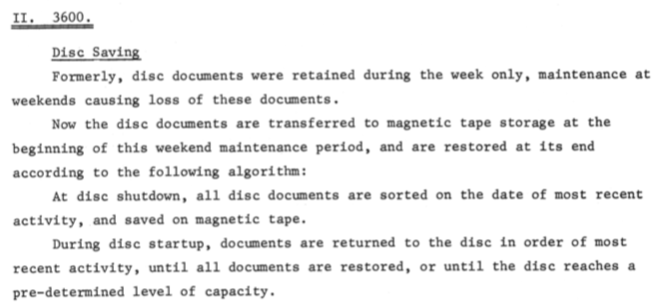


Once users were able to retain documents on on-line storage, the management of this became a problem, illustrated by changing strategies to deal with it. It is gratifying to note how the service continued to grow in supporting users, by providing off-line storage for the overflow.

The 1971-1972 Annual Report can be found here.
Development of DAD continued: additional disc and channels, support for up to 70 interactive ports, improved scheduling, reentrant code, and the virtualisation of the Document Region spanning drums and disc, with overflow to magnetic tape,; and system reliability (to support interactive use).



{kind=link}
{kind=link}
{kind=link}


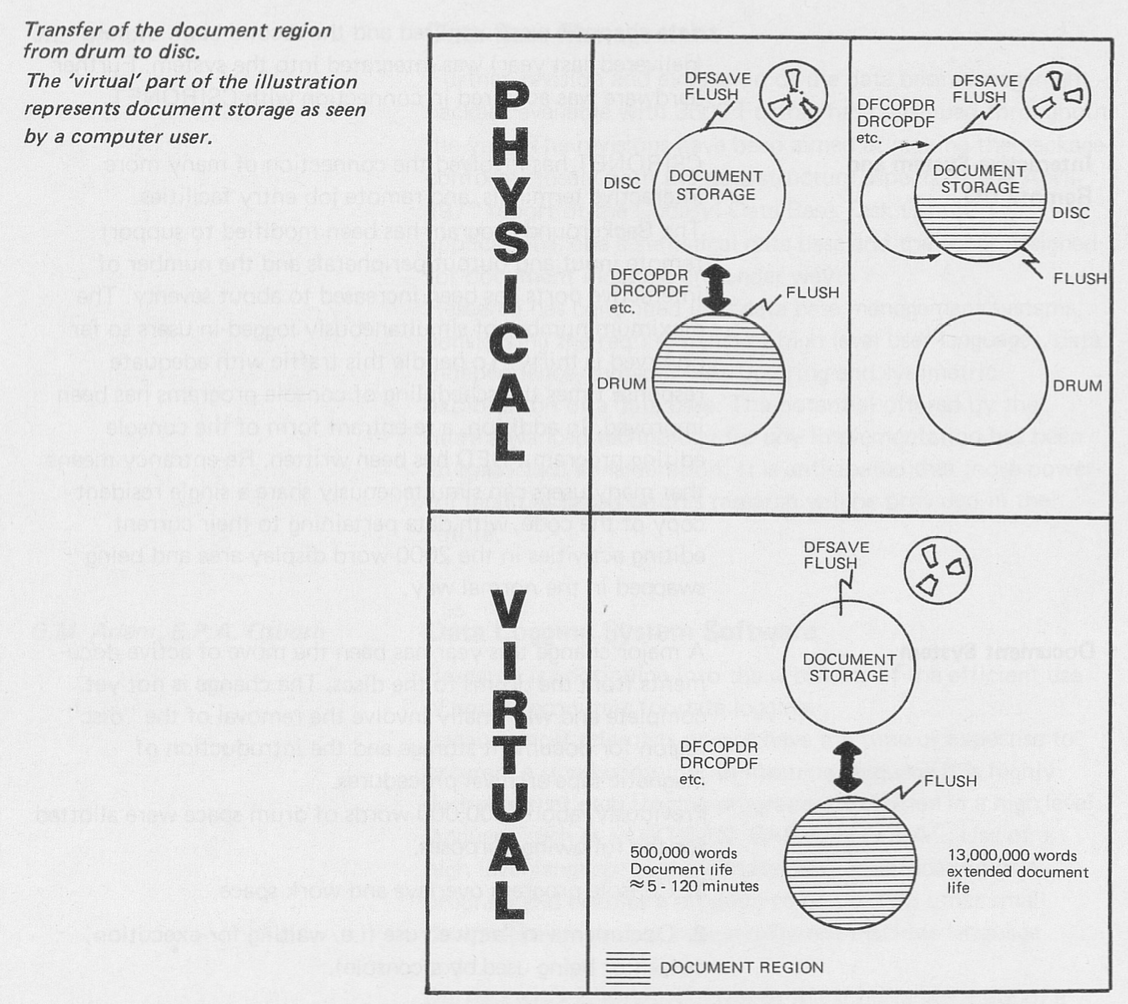
C.S.I.R.O. Division of Computing Research – Newsletter No. 92 – May 1973 contained a lot of information about the upgraded Document Region. Retention periods were introduced for documents, allowing users to specify how many days each document was to be retained. But, there was a sting in the tail: charges for the full retention period were imposed at the time a retention period was specified! This encouraged the use of short retention periods, though these could be extended (with immediate charges for the extended period!).
Copies of unexpired documents were made onto tape weekly. If the document’s retention period was long enough, it was copied to two tapes (“for security reasons”). After this, the document may be flushed. These are exactly the HSM processes which are in operation on the CSIRO Scientific Computing Data Store today – migrate data from disc to tape, and free up disc space for migrated files – except that retention periods are not defined, and are taken to be infinite.

And, here is the counterpart to migration – automatic recall or retrieval. And, there was integration with the job scheduler, and batching of requests for reasons of efficiency.


Finally, users were able to view their holdings in the system, and issue explicit requests for recall or retrieval – the equivalent of the dmget command which has been in operation on CSIRO SC systems from 1991 to today.

And the previous explicit use of the disc storage system was being phased out to make room for the integrated automatic document region.

The 1972-73 DCR Annual report can be found here.
The Document System continued to be enhanced, supporting user-specified retention periods, and automatic retrieval from tape, thus providing one of the earliest Hierarchical Storage Management system.

Some primitive level of security was introduced.

With the arrival of the Cyber 76 in 1973, attention focussed on integrating it with the 3600 and the network, and developments of DAD, apart from the essentials to facilitate the above, effectively ceased, along with any changes to the Document Region. The Cyber 76 had is own ‘permanent’ file system, but DCR never developed the service into the HSM that DAD provided. With the de-commissioning of the CDC 3600 in the second half of 1977, the Document Region met its demise.
In the early 1980s, DCR acquired a Calcomp/Braegan Automated Tape Library and developed its Terabit File Store on top of that, providing an archive system with a hierarchical file system, but never provided the automatic tiering (migration, releasing and recall) that the DR provided.
Since the TFS required explicit commands to access files, I built and made available to other users a command called tattach. The attach command was the standard way of making files under CDC operating systems available to jobs. For example,
attach(lfn,myfile,id=cmpxrb)
would make available to the job the permanent file called myfile under the local file name lfn. Subsequent job steps could then reference lfn: e.g. with commands like:
copy (lfn,newcopy)
The tattach command would first check for the presence of a file in the permanent file system, and if present, attach it; and if not present would run the required commands to retrieve the file from the TFS, wait until retrieval was done, and then attach it.
This delivered HSM-like automatic recall capabilities on top of the TFS.
Here’s an example command:
tattach,lib,$blktrb.lib$,id=cmpxrb,sn=cmp9007,xr=[danger],cy=1.
A presentation on the beginnings of tiered storage in CSIRO is available in the Resources Section under the title “Pre-history: the origins of HSM in scientific computing in Australia”. This contains snippets from DCR Newsletters from 1966 to 1980.
We saw:
- the introduction of on-line digital storage (drums and disc)
- the development by CSIRO and CDA of an operating system to support the Drums and Display (DAD)
- the beginnings of shared storage management, flushing, and Hierarchical Storage Management (HSM) using 3 tiers of drums, disc and tape, with automatic movement between tiers in response to demand and user requests. This level of automation was not to be repeated in CSIRO until 1993.
The management of shared storage
The above section revealed some of the story of the beginning of shared digital storage in CSIRO, and the challenges of managing it.
This section will deal with some of the later history of how CSIRO managed the digital storage facilities that were shared by the users of the HPC systems.
Problem of shared filesystems
In May 2005, I started to list some characteristics that users want from storage:
- every file kept and backed-up
- only one file system
- globally visible across all the systems they use
- high-performance everywhere
- infinite capacity
- zero cost
- utterly reliable
- always available
- low latency
- no HSM!
In later years, I noted:
- There are many reasons why this is not possible: principally financial, but there are the constraints caused by worsening ratios of bandwidths to capacity, the trade-offs between wide accessibility and performance (e.g. caching decisions), and the rapidly growing demands for capacity.
- We provide a range of filesystems, each meeting some of the needs.
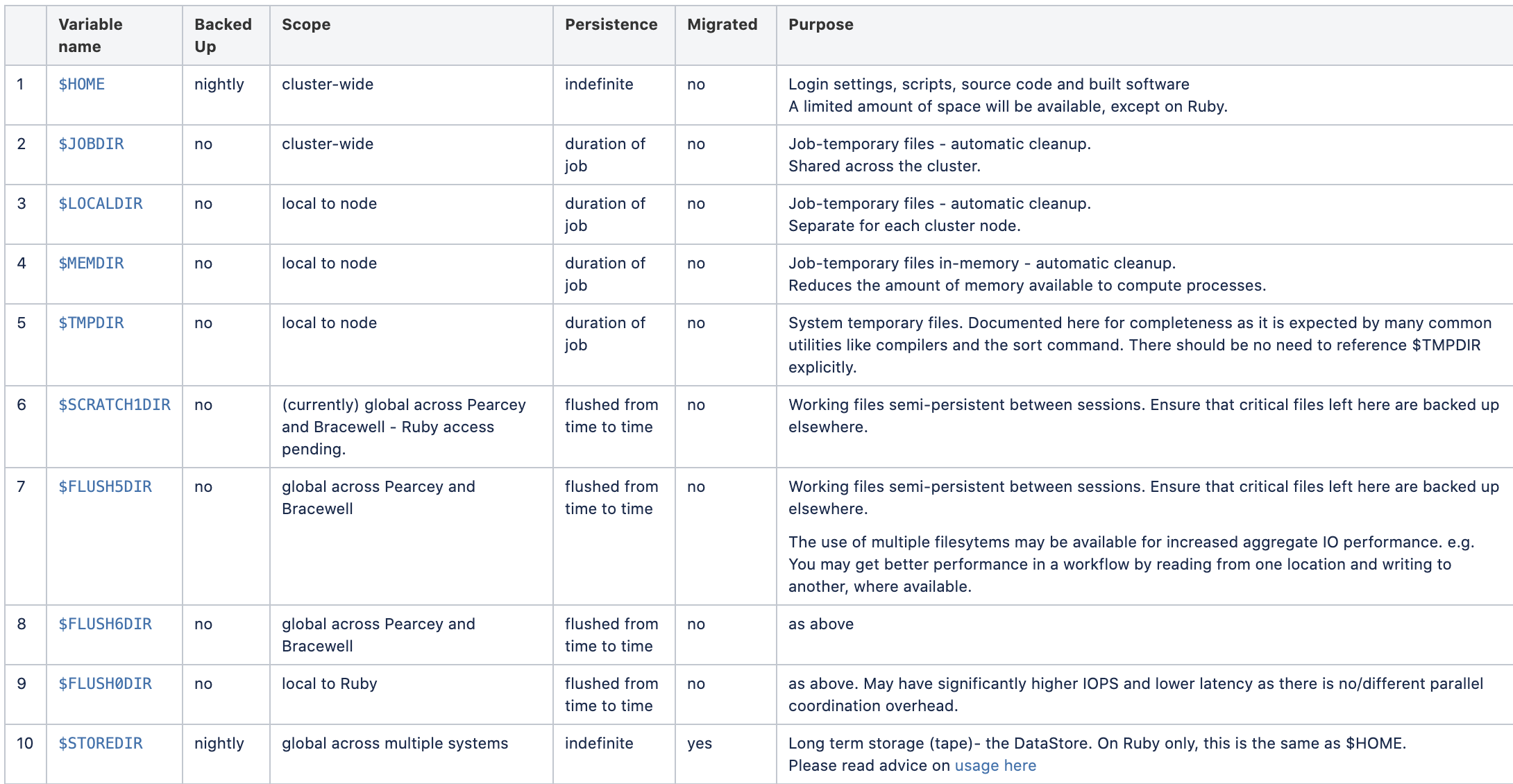
The range of filesystems usually include a relatively small area with backups provided, large areas with high performance for running jobs, and a large area for long-term storage. CSIRO has used the Cray Research/SGI/HPE DMF product since 1991 to provide large-scale protected data storage using the Hierarchical Storage Management technology. Since about the year 2000, CSIRO developed its own efficient backup technologies based on the rsync utility and extended Tower of Hanoi management for some areas, and its own scalable flushing algorithm for removing the older files from the shared areas designated for short-term storage only. CSIRO also developed procedures for dealing with the files left behind by staff who have left the organisation. CSIRO has in recent years developed a Data Access Portal for the management of research data.
Here is a sample of a range of filesystems available on a system, with the range of management techniques used. This illustrates that no single filesystem can meet all the users’ needs.
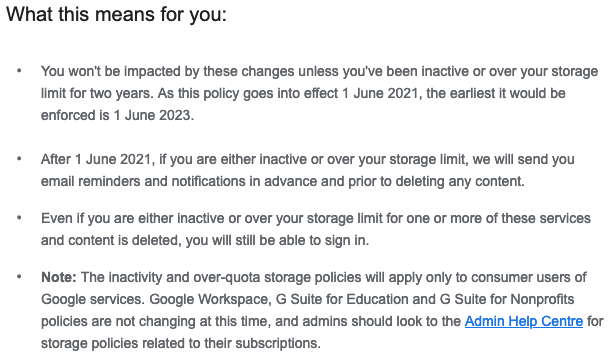
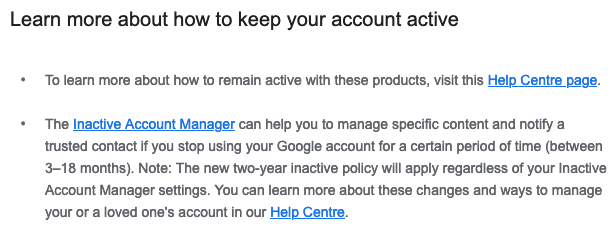
It’s interesting to see in December 2020 that even Google is taking steps to control usage of its shared storage: in particular, the removal of dormant files. Here is the e-mail: