Sidebar 6: Robert Bell personal computing history
Sidebar 6: Robert Bell personal computing history
Last updated: 22 Jun 2026, to add more dates, and a link to early memories at Aspendale.
23 Jun 2025: added more about DMF and transition.
Robert C. Bell
Largely complete.
2021-09-20 – added note about colleagues.
2021-10-25 – expanded the quote from Paul Davies.
2023-08-12 – spelling correction, and note about QBO.
2024-05-17. Added material about DCR interactions – computing costs.
2024-05-20. Added material about resource allocation, scheduling and job progress.
2024-06-17. Fixed some typos.
2025-11-19 to 2026 Jan 07. Added storage mantras; added link to “Death of Data” talk.

Rob Bell with CSIR Mk 1 (CSIRAC) at the Melbourne Museum.
Contents
Introduction
In 2003, I gave a talk at a Dinner hosted by RMIT Engineering, and talked about my career in terms of Technology: Mathematics, Meteorology, Machines.
Early life
Maths and School, and first computing

University and Vacation Employment
I again worked at CMRC in 1970-71, and wrote a report on the work: Comparisons between explicit and semi-implicit time differencing schemes for simple atmospheric models
Post-graduate
CSIRO Aspendale
ITCE
C———————————————————————–
C
C WA IS THE FIRST OF THREE PROGRAMS TO ANALYSE I. T. C. E. CORE
C DATE FROM MAGNETIC TAPE
C THE MAIN STAGES OF WA ARE:
C 1. SETUP AND INITIALIZATION
C 2. INPUT OF FUNCTION SPECIFICATIONS FROM PAPER TAPE FROM THE
C 21MX.
C 3. INPUT OF SPECTRA SPECIFICATIONS FROM PAPER TAPE FROM THE
C 21MX.
C 4. PROCESSING OF BLOCKS OF DATA FROM MAGNETIC TAPE. THIS STAGE
C CONSISTS OF –
C A. INPUT FROM MAGNETIC TAPE.
C B. CONVERSION TO VOLTAGES.
C C. SELECTING THE CORRECT SUBROUTINE FOR CALIBRATION.
C D. COLLECTING SUMS FOR AVERAGING, ETC.
C E. OUTPUTTING REQUIRED CALIBRATED DATA TO DISC FOR SPECTRA.
C 5. CALCULATION AND PRINTING OF AVERAGES, ETC.
C 6. OUTPUT OF CONTROLLING DATA AND AVERAGES, ETC. FOR WB AND WC.
C
C NOTE. THROUGHOUT THIS PROGRAM, THE WORDS FUNCTION AND
C SUBROUTINE ARE BOTH USED TO DESCRIBE THE EXPERIMENTER-
C SUPPLIED SUBROUTINES.
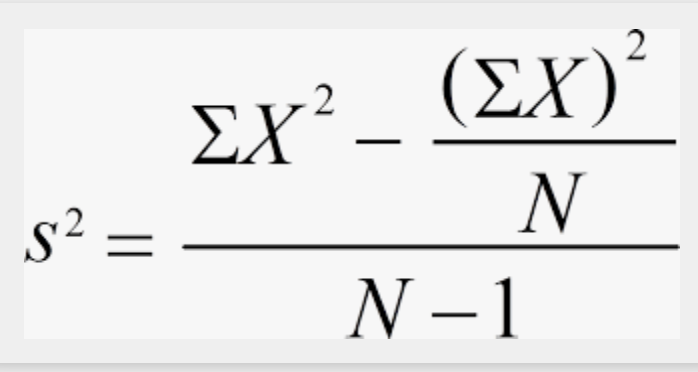
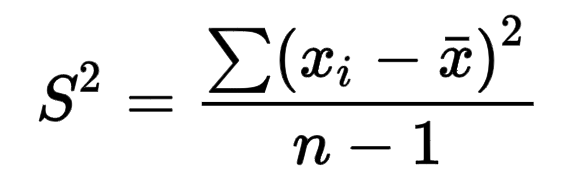
Collaborations
UK Met Office visit
Jorgen Frederiksen
DCR/Csironet interactions and charging
DAR Computing Group
SFTF
I was heavily involved and managed the benchmarks that were assembled from codes from several CSIRO Divisions, along with some specific benchmarks to test key areas such as memory performance. I travelled with Bob Smart to the USA for two weeks to undertake benchmarking and to explore options. This was our first visit to the USA. We visited Purdue University, which was running UNIX on an ETA-10, and still running a CDC 6500 system. We visited Control Data in Minneapolis, then Cray Research at Mendota Heights and Chippewa Falls. We visited Convex in Richardson Texas, and finally the National Center for Atmospheric Research in Boulder Colorado for the Users Conference. One of my benchmarks measured the performance of code using varying strides through memory, and showed dramatic decreases in performance with large strides on systems without ‘supercomputer’ memory architecture. I presented results at the Third Australian Supercomputer Conference proceedings in 1990 under the title Benchmarking to buy.
JSF and SSG
CUG and DMF
DMF
CSF
Cost write-back, the Share Scheme and the Development Fund: STK Tape library
CSF Collaboration
Utilities – the tardir family
America Cup

Bureau of Meteorology – HPCCC
The naming of the SX-4 caused contention – the Bureau staff wanted to continue the Bureau’s naming scheme based on aboriginal names, but that was seen by CSIRO staff as cementing the systems as being part of the Bureau, not part of the new joint entity, the HPCCC. Eventually, the system was named bragg after eminent Australian scientists, and this convention continued in the HPCCC to florey, russell, eccles, mawson, and in CSIRO to burnet, bracewell, ruby, bowen, pearcey.
HPCCC – SX-6 era, 700 Collins St, SGI storage management, clusters
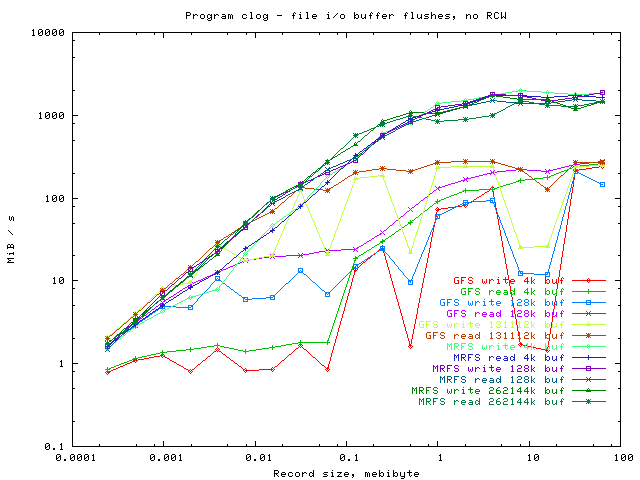
The performance climbs as the record size increases, as the buffer size is increased, and when switching from the disc-based GFS to the memory-based filesystems.
National Facilities
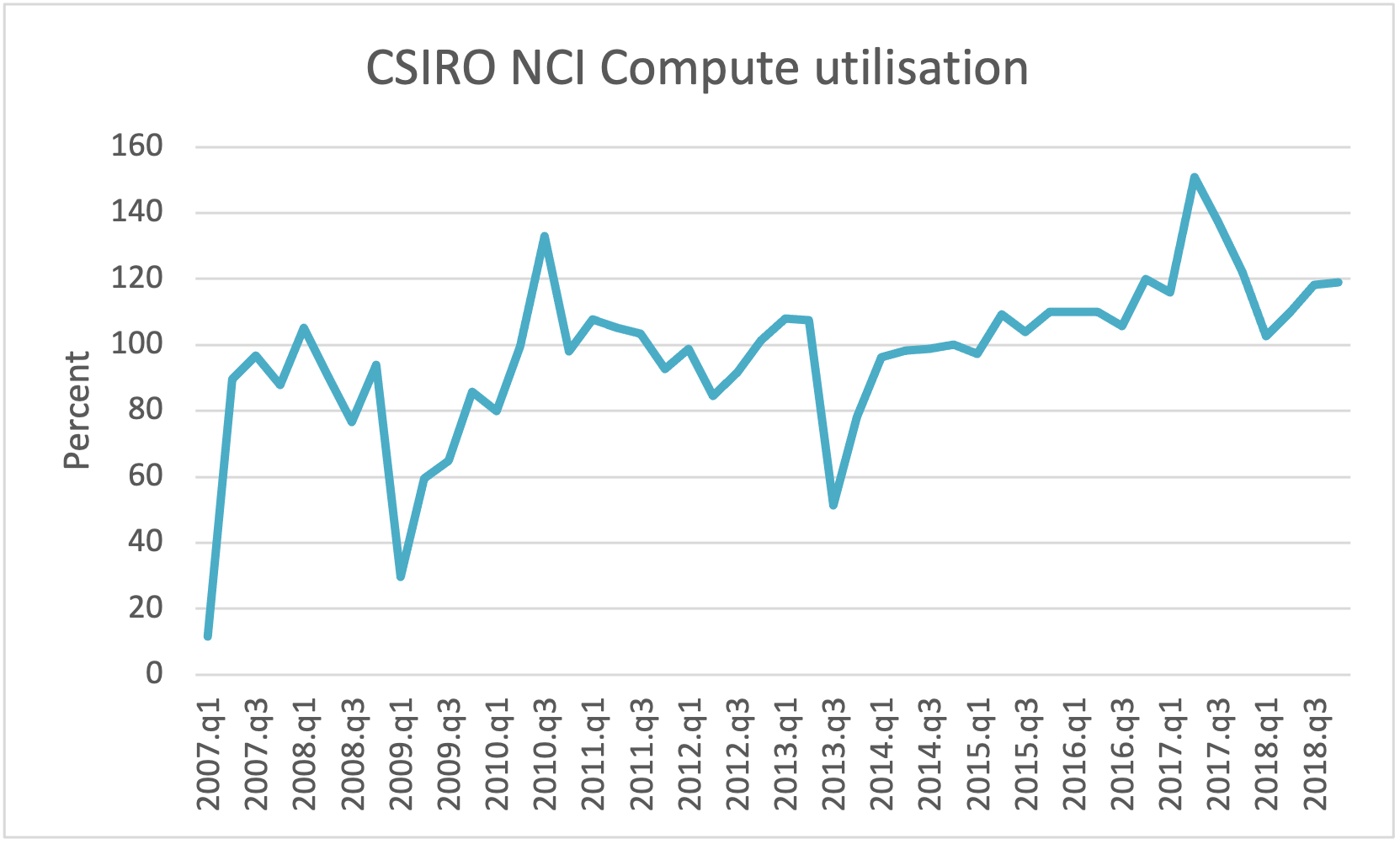
From 2014, I was tasked with managing CSIRO’s use of and interaction with National HPC facilities, such as NCI, the Pawsey Centre and MASSIVE.
For NCI, I managed the allocation process with the aim of maximising CSIRO’s use of the facilities. This involved setting initial allocations each quarter, but increasingly I was able to adjust allocations through each quarter – giving more allocation to projects that were running ahead of their pro-rata allocation, and taking allocation away from dormant projects. This was not part of the original allocation model, but was important to avoid wasted resources towards the end of each quarter as allocations would have otherwise sat in projects that were not going to use the allocation. With the aid of the ‘bonus’ facility (allowing projects whose allocation was exhausted to still have jobs started when otherwise-idle conditions arose – subsequently withdrawn by NCI), CSIRO was able to drive utilisation of its share to high levels.
Software
This section highlights some of the software I designed or developed in the 21st Century, to support the users and the systems for CSIRO Scientific Computing. The tardir family and the clog benchmark were mentioned above.
Time Create Delete
In 2007, when developing the clog benchmark (see above), I also developed a simple test of the performance of filesystems on metadata operations. This simple test timed the creation of about 10,000 nested directories in a file system, and timed the deletion of them. (A similar test was run in 1997 during acceptance tests on the NEC SX-4, and was abandoned incomplete after about 10 days.) Many operations on files do not involve bulk data movement, but do involve scanning filesystems to retrieve metadata, e.g. for backups or for scanning for files to be flushed (see below). I ran the tests on several systems around 23:00 each day, to allow for monitoring of the performance over time. Of course, there was a lot of variation in performance from day to day, because the tests were run on non-dedicated systems. Also, the test results depend on not just the underlying storage performance, but on the operating system – caching could have come into play.
Here’s an example of the performance of several filesystems, run from one of the SC cluster nodes.
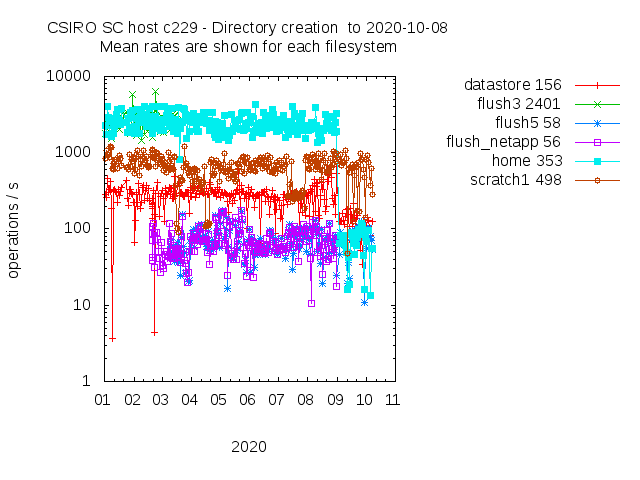
There was a reconfiguration in September 2020 which led to reduced performance of the /home filesystem, and the /datastore filesystem (NFS mounted from ruby).
Job progress
I developed scripts to monitor the progress of jobs on a compute system. This was especially important on the HPCCC systems where operational jobs were deployed. Below are two samples of non-operational jobs running on a over-committed nodes, where initial progress is slow, then the jobs speed up and finally reach full speed towards the end. This type of workload benefitted from the varying process priorities as implemented by Jeroen as described above.
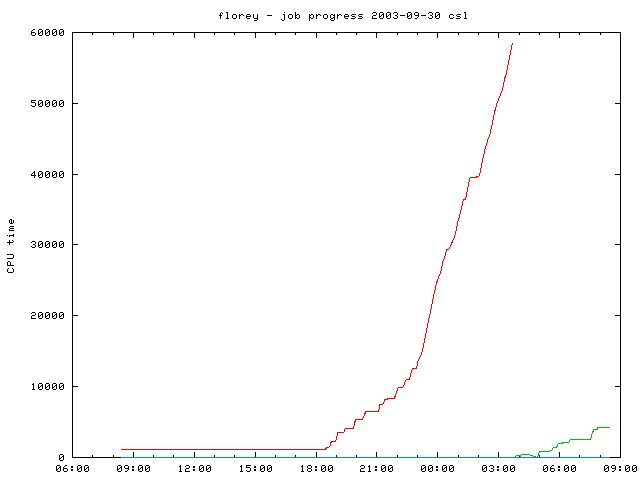
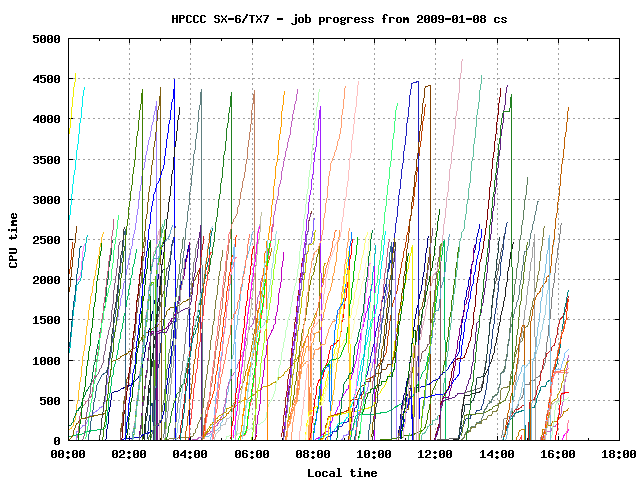
Over-commitment (allocating jobs to a node so that the sum of the number of requested CPUs was more than the number of CPUs on a node), allowed jobs in their early stages to soak up small amounts of otherwise idle time. Over-commitment was not done for large multi-CPU and multi-node jobs, that required dedicated resources for maximum throughput.
STREAM2
John McAlpine developed the STREAM benchmark to measure the bandwidth between processors and memory, since this aspect of computer performance was often of more importance than pure processing speed for real-world applications. He started developing the STREAM2 benchmark, which measured memory bandwidth for a range of data or problem sizes, and I developed the benchmark further. Later, Aaron McDonough took over the management of running the benchmark on the systems available to CSIRO users, to show some of their characteristics.
STREAM2 exposed the memory hierarchy on cache-based processors, and showed the strength of vector processors which were supported by cross-bar switches to many-banked memory systems, such as the Cray and NEC vector systems. Here is an example of the results of running the DAXPY test of STREAM2 on a range of systems available to CSIRO users in 2004.

(The scale is in Mflop/s – for the DAXPY operation that requires 12 bytes/flop, 1 Mflop/s corresponds to 12 Mbyte/s memory traffic.)
The cache architecture is evident for the microprocessors, with an order of magnitude lower bandwidth than the NEC vector system, whose memory bandwidth is uniformly good after a threshold is reached.
STORE/RECALL
CSIRO Scientific Computing and predecessors has run the DMF Hierarchical Storage Management system since November 1991.
At various stages, other products and configuration were evaluated. At the time, there appeared to be no benchmark tests available for HSMs, so I started one in 1996.
The idea was to simulate and measure the data transfer rates for a notional user who ran a Fortran program (such as a climate modeller) to produce a stream of data, starting in memory, then on fast disc, then on slower disc and then to a secondary storage medium such as magnetic tape. That was the store part of the benchmark. The recall part was to recall the data for processing, reversing the flow through the layers above. Of course, the data sizes I used in the late 1990s were far smaller than current computing allows.
Some of the ideas for this benchmark came from the Hint benchmark.
Here’s a graph showing the speed of storage (Mbyte/s) as a function of the progressive amount of data stored. This was run on an SGI Altix in 2012 using DMF.
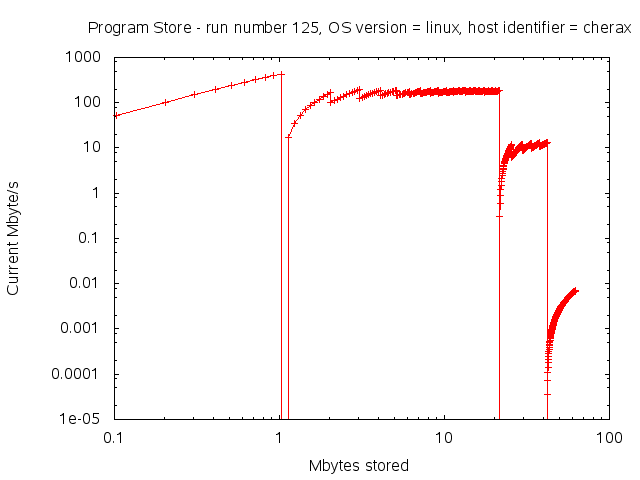 The 4 tiers of storage can be seen clearly, with their corresponding transfer rates. Tiers 2 and 3 appear to have reached their asymptotic speeds, but tiers 1 (memory) and 4 (tape storage) were not fully pressured.
The 4 tiers of storage can be seen clearly, with their corresponding transfer rates. Tiers 2 and 3 appear to have reached their asymptotic speeds, but tiers 1 (memory) and 4 (tape storage) were not fully pressured.
Here’s the corresponding graph for the recall.
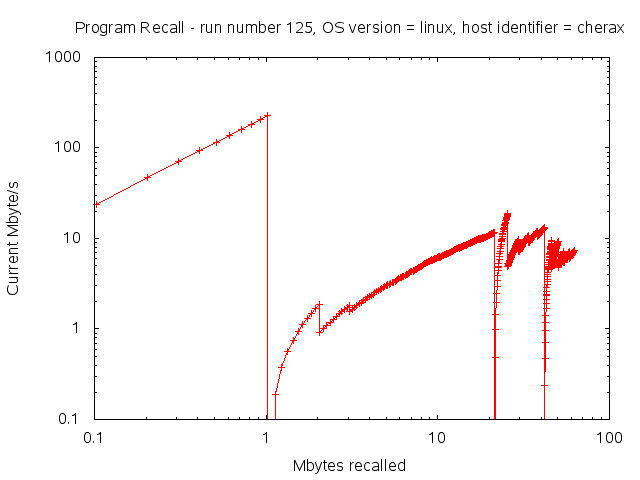
Again, the 4 tiers are visible, but the data sizes were not large enough to push each tier to its maximum performance. It seems that the tape recall was as fast as the disc reading.
This benchmark could have been a useful tool to evaluate storage systems from the point of view of a user with ‘infinite’ demands.
Traffic Lights
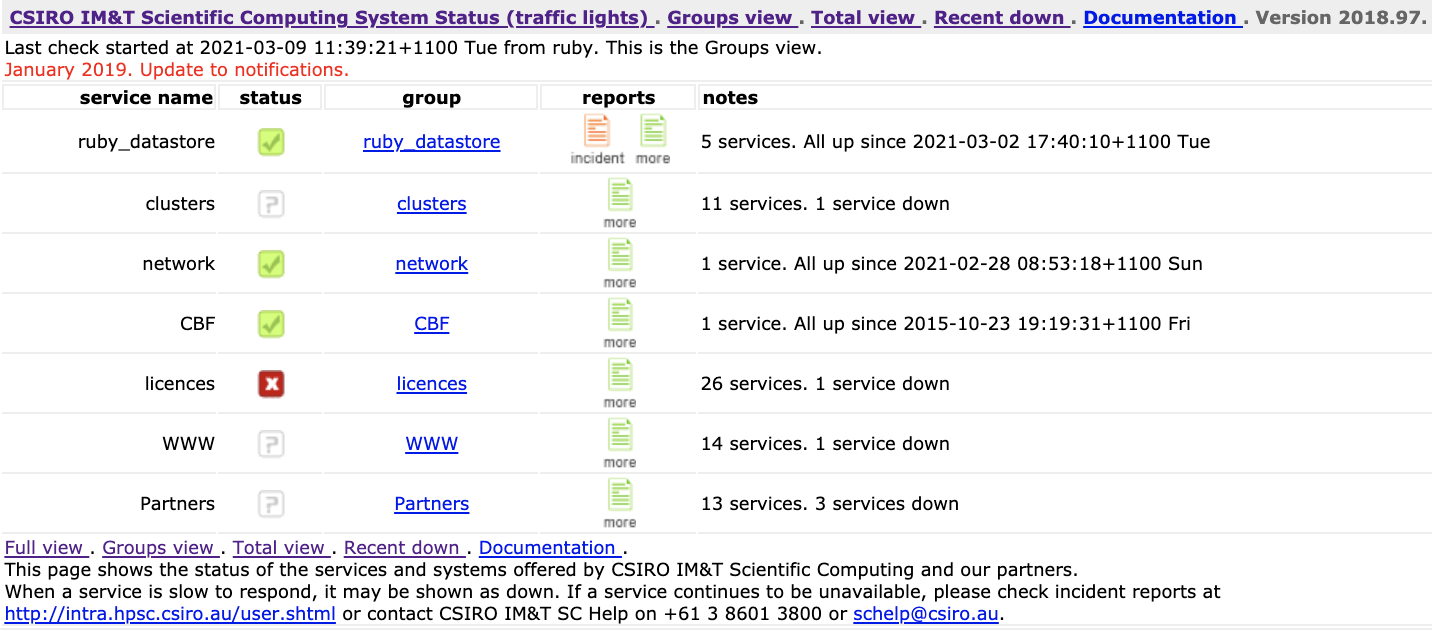


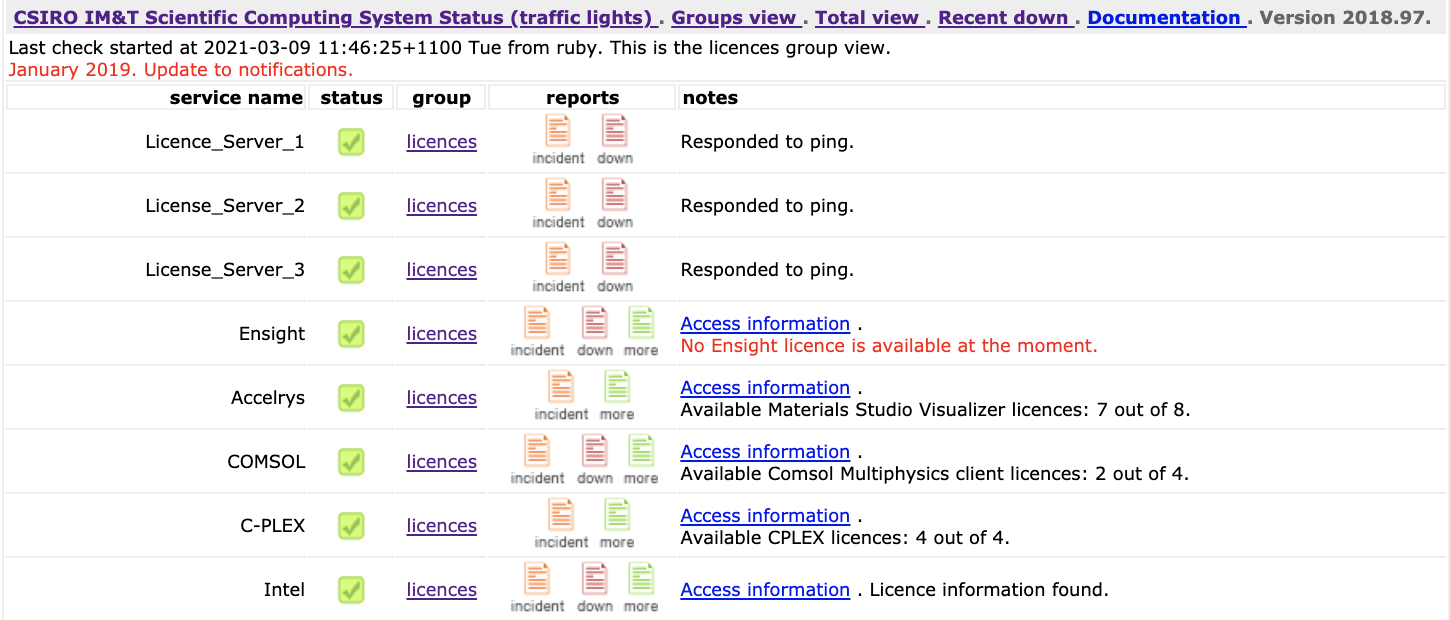
Backups, data protection, data management, the Scientific Computing Data Store
Users typically want every file kept and backed-up, and would be happy to use only one file system, globally visible across all the systems they use, with high-performance everywhere, and infinite capacity! A user added that they want all of the above, at zero cost!
There are many reasons why this is not possible: principally financial, but there are the constraints caused by worsening ratios of bandwidths to capacity, the tradeoffs between wide accessibility and performance (e.g. caching decisions), and the rapidly growing demands for capacity.
This became one of my mantras about storage: here are the others.
- “Off-line data is dead data”, or at least dying. Only by keeping the data under the control of a system can the data be refreshed onto new media types or new formats. The idea that putting data onto CDs preserves it, is laughable. Bob Smart reckoned that this mantra should be called Bell’s Law.
- We spend more effort in managing the storage and data than in managing the computational facilities.
- Flops may come, and flops may go,
But bytes go on forever.
Tennyson, “The Brook” - We keep everything: we can’t find anything!
- HPSC: We store it, we don’t manage it: it’s a start!
- A resource divided is a resource diminished
- Buying more discs doesn’t solve your problem: it just adds to it!
- 2010-04-07. You’ve come here to compute: what you’ll be remembered for is the data you leave behind.
-
c. 2010: An HSM is for life, not just for Christmas (borrowing from an RSPCA advertisement about a pet.)
When I was acting as a consultant at the Arctic Region Supercomputing Centre in 2002, I conducted a review of its storage plans, and argued for two models of service: for those concentrating on HPC, they would be based on on the HPC servers, and would have to explicitly access storage servers. For those concentrating on working with data, they would be based as close to the storage as possible, i.e. directly using an HSM-managed filesystem, and would have to explicitly access HPC servers, e.g. by using batch job submission. This model continued through to 2021, with cherax and ruby SGI systems providing a platform for data-intensive processing, in tandem with HPC systems. Part of the inspiration for this model and these systems was a comment from one of the climate modellers, that the modelling was done (on the HPC system of the time), but he was so far behind in the data analysis.
These systems, and the closely-associated Data Store became one of my flagship endeavours, in attempting to provide users with a single large space for storing and working with data. Although the migrating filesystem for the /home area took some getting used to (because inevitably, the file you wanted was off-line), users with large data holdings valued the system for its unitary nature, and coded workflows to build pipelines allowing for efficient file recalls and file processing. Peter Edwards enhanced this experience by enhancing the dmget command to allow large recalls to be broken into carefully crafted batches, one for each tape needing to be accessed (stopping denial of service from a user requesting huge recalls), and allowing the interlacing of recalls and processing of batches of files. He also enhanced the dmput command, to allow one user to work with another user’s data and not cause problems with space management for the owner of the data. Here are the man pages for the CSIRO-modified dmput and dmget commands.
One day in about 2007, Jeroen reported to me that there was a new facility in the rsync utility which might be of interest. Jeroen had taken over management of the backups on the CSIRO systems. The rsync utility, written by Andrew Tridgell at ANU, allowed efficient mirroring of files from one location to another, avoiding unnecessary transfers. The new feature was the –link-dest= – this allowed an rsync transfer from a source to a destination to be able to consider a third location (such as the previous day’s backup), and instead of transferring an identical file, just make a hard-link. The backups then because a series of directories (perhaps one per day), with there being only one copy of files common to multiple backups, but each directory appearing to be a complete or full backup (which it is). This has the advantage of providing a full backup every day, for the cost of an incremental backup – i.e. transferring only changed or new files.
Jeroen coded this into the backup suite, and he and I also developed Tower of Hanoi management of backup holdings. We used a DMF-managed filesystem as the targets for the backups, taking advantage of the in-built tape management. After Jeroen left, Peter Edwards took over the systems administrator. He and I continued to develop the capabilities of the backup suite, including the work by Peter to develop a directive-based front-end to specify filesystems to be backed up. Peter also found that a filesystem could be mounted twice onto a system, with the second mount being read-only. This allowed the backups of the users’ home filesystems to be made available on-line to the users, allowing for inspection and restoration. We did consider patenting some of the ideas, but instead made the ideas freely available. Here’s a picture of Tower of Hanoi puzzle.

I gave several talks on the backup suite: the first one, given to the DMF User Group in 2009 was entitled DMF as a target for backup. The key features are:
The techniques in use provide:
1. coverage back in time adjusting to the likelihood of recovery being needed
2. full backups every time, for the cost of incrementals
3. simple visibility of the backup holdings
4. simple recovery for individual files and complete file systems
5. no vendor dependency
6. centralised tape management
7. space saving of about a factor of five compared with conventional backups
8. directive-driven configuration
9. user visibility and recovery of files from the backups
The key utility for doing the Tower of Hanoi and other management is in a script called purge_backups.pl, started by Jeroen, and stretching now to 5740 lines. A note I wrote about some of the extensions to the original Tower of Hanoi management is at the Wikipedia page Backup rotation scheme under the heading Extensions and example.
In 2009, I gave a poster presentation at the eResearch conference entitled, Your Data, Our Responsibility.
The poster outlined some storage dilemmas for HPC centres, and then advocated the use of HSM, the use of the rsync utility and Tower of Hanoi management scheme for backups, using CSIRO’s experience as an example.
This backup suite continued to protect systems and user filesystems until 1st March 2021, when backups of the cluster home filesystems were switched to use the in-built snapshots capability, and Commvault.
The graph below supports the assertion that full backups were achieved at the cost of incrementals. It shows the ratio of files moved in a month to total files being considered.

The ratio is about 0.1, or 10%. The ratio of data moved in a month to total data being considered was about 0.4. For daily backups, this means a reduction by a factor of about 75 in data moved compared with full backups every day.
The collage shows various other statistics from the backups.
(New storage for the backups with front-end SSD was utilised from 2014 onwards, providing better performance.)
Flushing
Jeroen van den Muyzenberg started with CSIRO as systems administrator in 1999. He successfully wrote scripts to handle flushing of temporary filesystems in a rational way from December 2000. One script monitoring the target filesystem, and if it was more than a threshold (such as 95%) full, triggered another script. This used the large memory on the SGI systems to slurp in details of the entire holdings on the target filesystem. This list was then sorted (based on the newer of access and modify times), and the oldest files (and directories) were removed. This worked successfully for several years.
However, in 2016, flushing was needed for the CSIRO cluster systems, which did not have a big memory, and indeed the filesystems were hosted on servers without a large memory, which were the most suitable hosts for such housekeeping operations. Around that time, I read an article It Probably Works by Tyler McMullen in the Communications of the ACM (November 2015, Vol. 58 No. 11, Pages 50-54).

I realised that we don’t need to know the oldest file to start flushing – we just need to know a collection of the older files. This led to an algorithm which scanned a filesystem, and registered the files in ‘buckets’ according to their age. This removed the need for a sort. Then it became apparent that the scan could be performed in advance and the results saved, ready for a flushing process when needed. This separation of scanning and flushing meant that the system was always ready when a flush was needed, and in practice the flushing could be started within a few seconds from when a monitoring process signalled that flushing should be started. The only extra step for the flushing was to recheck for the existence of a candidate file, and whether its access or modify times were still within the range of the bucket.
The bucket boundaries were determined from the date of the start or last flush of a filesystem at one end, and a cut-off period, e.g. 14 days; we guaranteed to the users that we would not invoke the flushing on files younger than 14 days old.
The implementation was done by Steve McMahon from March 2016, with additions by Ahmed Arefin and Peter Edwards who added some production hardening.
Here is a list of features:
- New scalable flushing algorithm
- Separates scanning from flushing
- Eliminates the sort
- Can have lists ready for action in advance
- 2 second response time!
- Technical report available
- Open Source
- Allows increased default quotas
The scalable flushing code is in use on the CSIRO SC systems for 4 filesystems (March 2021). The graph below shows the action of flushing on a file system, showing the date of the oldest surviving files – flushes are marked by the vertical lines, reducing the age of the oldest surviving file.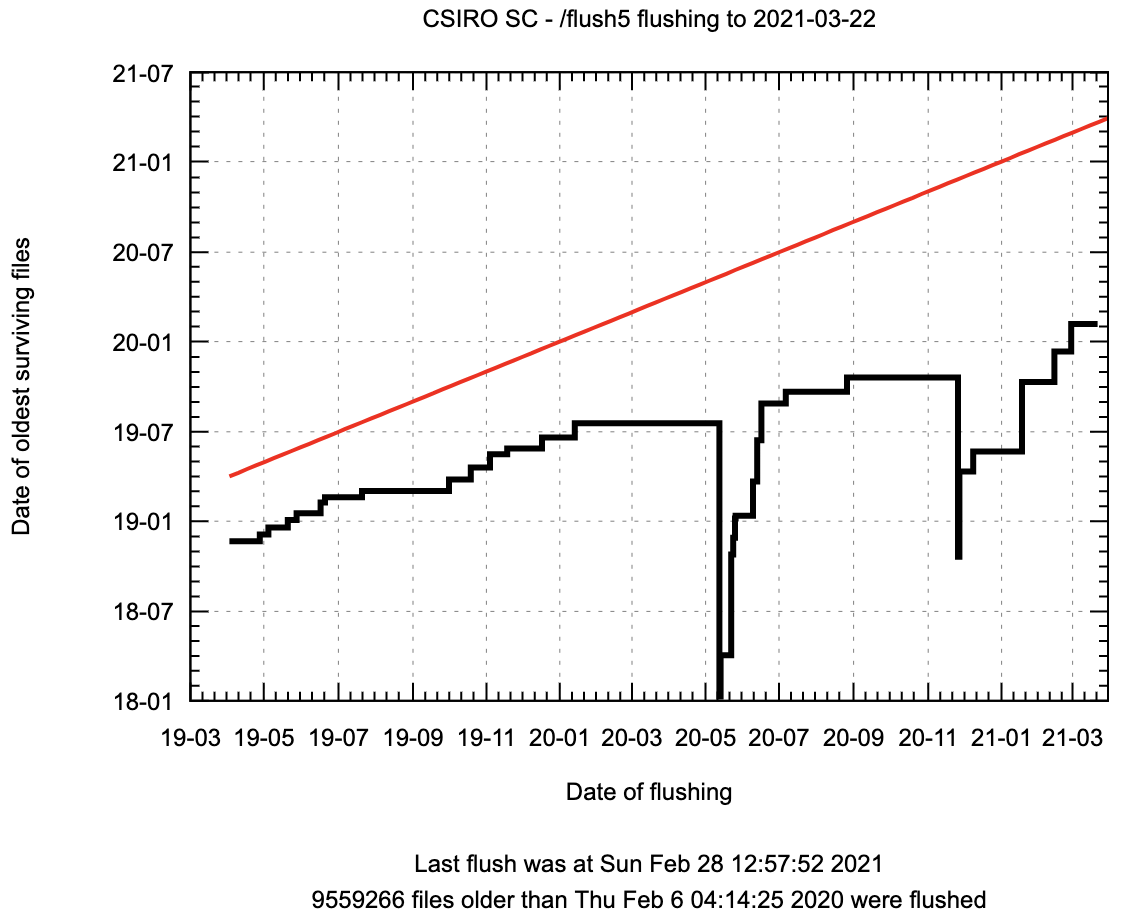
The next graph shows the the total space occupied by the files in each bucket. In this case, a flush has recently occurred, and the buckets marked in red have been processed.
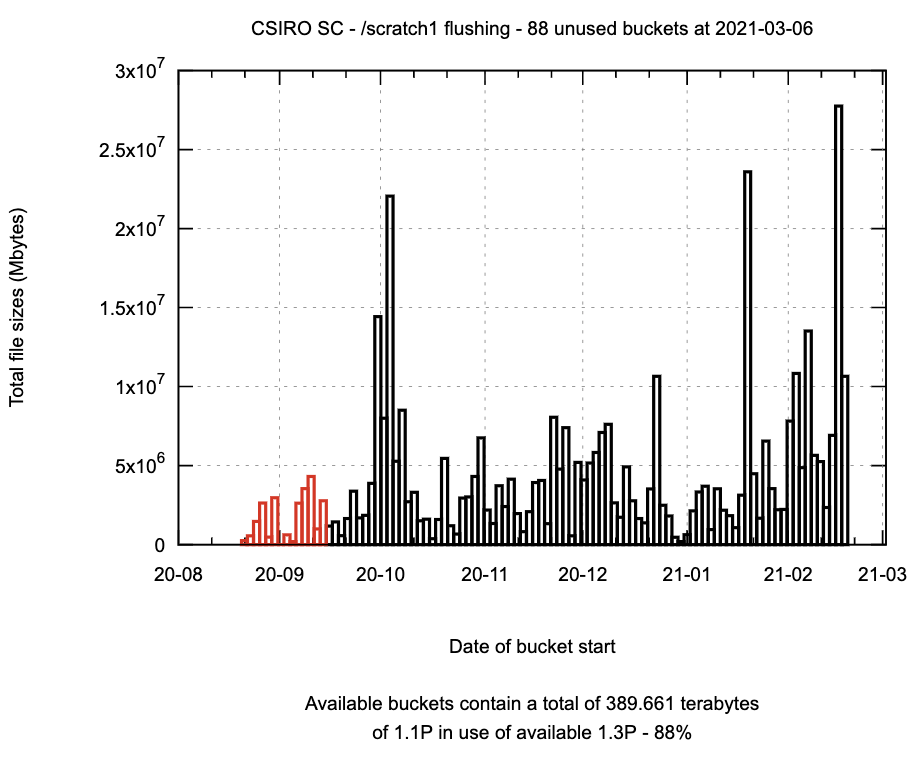
(The abscissa labels are of the form YY-MM, the last two digits of the year, and the digits of the month.)
Mirrors
In early 2018, CSIRO Scientific Computing started the process of removing a /data area from its systems. Here is a table of just some of the available filesystems on the cluster.
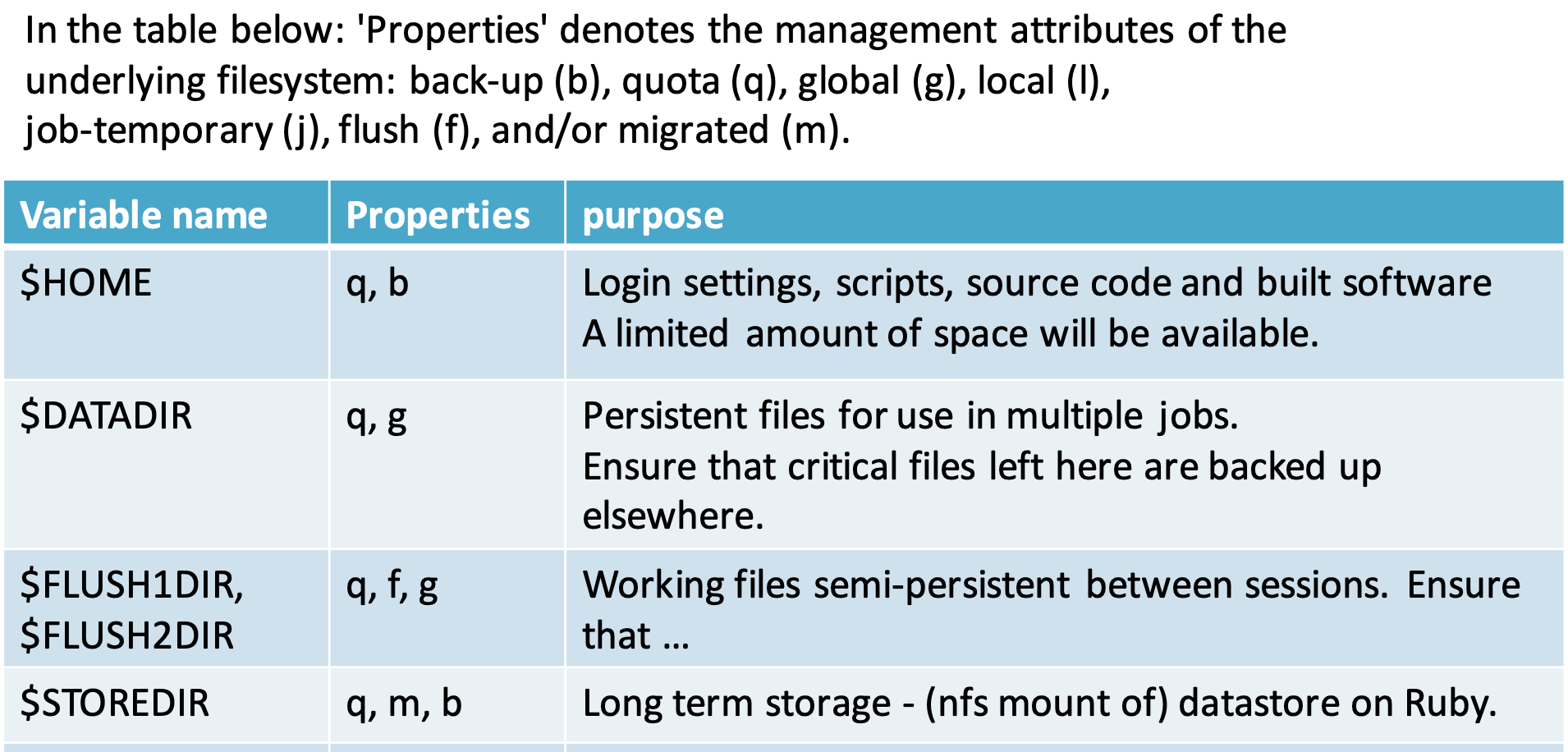
The /data area ($DATADIR) was subject to quotas, but when it filled, there was no good way to manage the holdings – no migration (HSM) nor flushing, and the old way of sending users a list of the biggest users (“name and shame”) was akin to bullying, in trying to use peer pressure to get users to remove old files. However, I wanted users to be able to maintain a collection of files on the systems bigger than the home file system could support, to be able to protect the files, but also not to lose files through flushing (when the only available space was a filesystem subject to flushing). In April 2018, I started on a utility to deal with mirrors of a working area. So, a user could set up an area on a flushable filesystem, then run the utility with
mirror.sh create
and a mirror of all the files would be created on the HSM storage ($STOREDIR) above, with intelligent consolidation of small files into tardir archives. If the user was away for a while, and some of the collection had been flushed, the user could restore the collection with the utility
mirror.sh sync
Other options allowed for the updating of the mirror. The utility was installed to run on ruby, the clusters, and the NCI systems. Later versions supported multi-host operations, such as providing a mirror on the CSIRO systems of a collection held at NCI. Here is a list of all the operations supported.
create sync update cleanse delete check status flush list help kill moveto explain dev_history release recall removetmp man restore auditw auditm verify config getremote putremote discover rebuild
Here is a link to a talk I gave in 2016 entitled “Death of Data“. The talk described the problems with managing so-called “data” or “project” areas, and the development of the mirror utility.
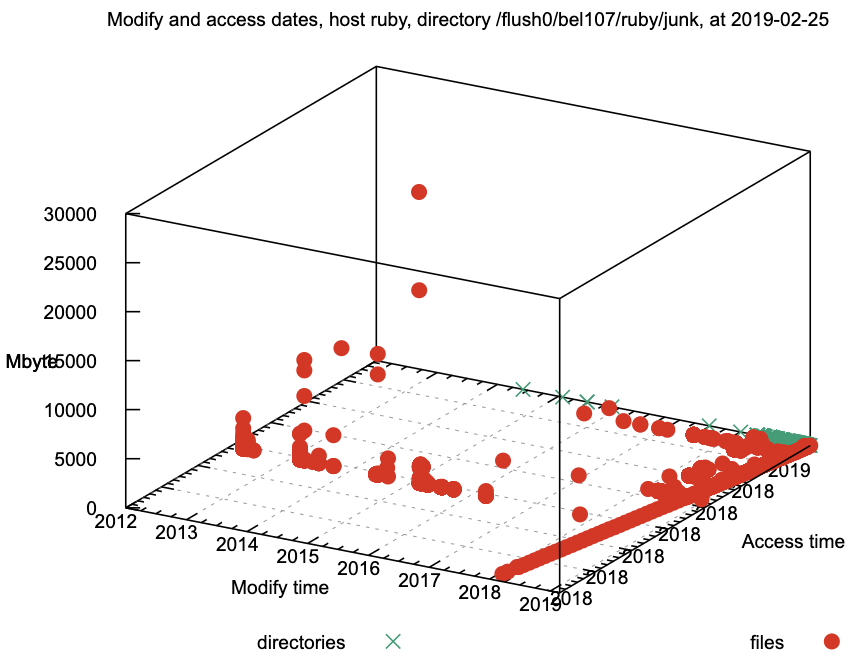
Utilities were also enhanced to allow profiling of the contents of an area – size, access time and modify time. Here is an example: when produced interactively, the plot could be rotated and zoomed.
Tenders, purchasing, acquisitions
A lot could be written about the major CSIRO computing acquisitions and the tender processes. The first one was about the responses to requests to build commercial versions of CSIRAC, and then the acquisition of the CDC 3600 and CDC 3200s. Later came the Csironet CDC machines, including the Cyber 205, and the Fujitsu systems.
Since the mid-1980s, I have been involved in acquisitions of the Cray Y-MPs and J90se, the HPCCC NEC SX-4, SX-5s and SX-6s and subsequent Bureau systems, the StorageTek tape drives and libraries, the APAC and NCI systems, the Pawsey magnus and storage systems, the Aspendale SGI and Cray J90 systems, the CSIRO cluster systems, the CSIRO Data Store hosts, software and disc storage, etc.
There is a story to tell for many of these. Some of the HPCCC NEC SX-6 tendering is documented in Chapter 7.
CSIR Mk I
The book The Last of the First, p ix, notes the attempt to commercialise CSIR Mk 1.
Attempts were made to interest Australian electronics firms in the commercial production of computers based on the CSIRAC design. In October 1952 Philips, EMI, AWA and STC were invited to tender for the construction of up to three machines. AWA and STC responded (there appears to be no record of interest from Philips or EMI), however, nothing eventuated from this exercise.
CDC 3200
There is a story behind the CDC 3600 and 3200 acquisitions by CSIRO and the Bureau of Census and Statistics, documented in an unpublished note taken from an address by E.T. Robinson, then manager of the CDC agent in Australia. Suffice it to say that although the 3600 was a real machine, the tendered auxiliary systems (called the 160-Z) did not exist at all at the time of the tendering, and the US head office did not know that the systems had been tendered. The Australian agent had to subsequently put it to CDC Head Office that it could and should design and build the systems, which became the 3200. Subsequently, the systems were installed but were underdone, particularly in the software area. The 3200 was the first in what was to become a very successful line of lower 3000 series machines.
I’ve told previously of the story of the CDA salesman who secured the sale of the Cyber 76, reportedly walking into a suburban bank branch in Canberra to deposit a $5M cheque into his personal bank account, and then transferring all except his commission to CDA the next day.
Reportedly, Peter Claringbold as Chief of DCR and head of Csironet arranged a major purchase or long lease of equipment without consulting the CSIRO Executive.
Aspendale
My first involvement started around 1986 with my appointment as Leader of the Computing Group in the CSIRO Division of Atmospheric Research at Aspendale. It was clear that the Division needed to move to having its own UNIX servers to support local processing. Already the CSIDA project had acquired Sun Microsystems workstations to support its image processing work, and the Division had a long history of using HP minicomputers running RTE for data acquisition and other tasks.
I set about drawing up requirements, and preparing a set of benchmarks to test contenders – these benchmarks included code such as Jorgen Frederiksen’s eigenvalue code which was running on the large Csironet machines. We expected Sun as the leading UNIX workstation vender at the time (SPARC), or the incumbent HP (PA-RISC) to provide the best solutions. I remember testing the codes on HPUX systems at HP’s office in Joseph St Blackburn, and finding that the compilers had difficulty compiling the code. SGI also submitted a tender, and we finished up testing the codes on an SGI system (MIPS) in Mike Gigante’s office at RMIT. To most people’s surprise, SGI won the contract, providing significantly higher performance than the other bids. This led to a SGI server (atmos) being installed for general UNIX processing at Aspendale.
This result showed two lessons, often not learnt.
- There is value in going out to tender, even when you think you know the best solution: the SGI proposal was not anticipated. SGI had embraced the value of a server rather than just one-person workstations.
- We can all get emotionally attached to what we are comfortable with, or perceive in our estimation as being the best result. The CSIDA group had its own solution (Sun), and did not embrace the SGI solution; nor did some of the Computing Group staff who had a long history with the HP minicomputers.
The Cray Research Era
Chapter 5 and the personal history above contain details about the process that led to CSIRO acquiring a Y-MP in the Joint Supercomputer Facility, and Chapter 6 contains details on the next Y-MP in the CSIRO Supercomputing Facility. The SFTF experience raised two lessons.
3. Benchmarks can provide performance information, but also expose the ability of the tenderers to demonstrate the capabilities of their systems, and show the strength (or otherwise) of their support capabilities.
4. Political considerations can often outweigh technical considerations. Despite the clear strength of the JSF Cray Y-MP proposal, there was resistance at a high level to the cost and risks involved, and the Convex solution was favoured. In the end, a chance circumstance led to the JSF Cray Y-MP proposal being accepted.
The HPCCC era
Chapter 7 and the personal history above contain details of the tender process for the first shared system for the HPCCC. The crucial issue for me was that although we had a scoring system for the responses from the vendors, we had not developed an overall methodology to cover the different rankings obtained by the Bureau and CSIRO. This led to two more lessons.
5. An overall ranking method was needed which gave weights to different factors.
6. Methods were needed to rank issues such as software quality, where Cray Research’s offering clearly outranked NEC’s. In the end, what could be easily measured, e.g. feeds and speeds, came to dominate the evaluation at the expense of more harder-to quantify qualities.
There was another issue at the time. The NEC solution was clearly not able to immediately deal with the management of data being carried out on the CSF Cray Y-MP with DMF. I insisted that a solution was needed to carry forward the (then) large quantities of data in a transparent way for the users. The only obvious way was to buy another Cray Research system, with a J90 being the obvious (cheaper) solution than the Y-MP, C90 or T90 systems. With the help of Ken Redford and John O’Callaghan, CSIRO was able to gain approval to acquire a J916se, another StorageTek tape library and tape drives to allow the transition of the Data Store. This led to another lesson.
7. It is possible to acquire significant systems without going to tender, but the case needs to be strong to gain approval levels (possibly up to ministerial levels).
This turned out to be a good decision, with the failure of the development work on the NEC SX-Backstore product to achieve production quality (see above). However, the J916se did have reliability problems, mainly around the Gigaring i/o architecture.
In 1999, the HPCCC decided for the final phase of the NEC contract to select an SX-5 rather than another SX4. A group from the HPCCC and the Bureau’s Research group visited Tokyo to evaluate the options, and came back and recommended the SX-5. This went ahead, and “florey” replaced “bragg”, the SX-4.
In 1999 with the 2000 Olympics looming in Sydney, the Bureau was keen to increase its resiliency by having a second SX-5. It received a proposal from NEC. CSIRO needed to make the choice of either matching the Bureau’s funding of the second SX-5, or go into an asymmetric funding arrangement for the HPCCC. Supporters of the HPCCC gained the approval of the Chief Executive, Malcolm McIntosh, for the multi-million dollar boost to funding for the HPCCC. Other senior members of CSIRO management were not happy that the money had been spent, particularly as the HPCCC systems were predominantly used by only a few Divisions of CSIRO – Atmospheric Research and Fisheries and Oceanography being the main users. Thus “russell” was acquired, installed and brought into production in time for the Olympics.
The Aspendale Cray J90 system (mid 1990s)
This was acquired to offload some of the climate modelling computations from the CSF Cray Y-MP. It also ran DMF – the value of the integrated storage solution was realised.
HPCCC SX-6 procurement (2002-03) – see above
The Sun Constellation systems for APAC and the Bureau (c. 2008)
See the NCI history here.
A decision was made in 2007-2008 for CSIRO not to continue the HPCCC, but to divert the funding into a system at ANU under NCI, with the Bureau acquiring a system solely for operations and operational development, but also to have a share of the NCI system for research computation. A joint NCI/Bureau procurement in 2008 in which I participated resulted in a contract with Sun for two Sun Constellation system – vayu at NCI and solar at the Bureau. Unfortunately, Sun was acquired by Oracle during this procurement, and Oracle did not have a focus on scientific computation.
8. RFQs should have the ability to consider and rate changes of company ownership when considering proposals.
The NCI raijin system (2012-2013)
NCI received funding for a new system, and proceeded to tender and the acquisition of a Fujitsu system – raijin. I was not directly involved with this one.
Towards the end of the process, three of the key staff at NCI left. One of the departures was David Singleton who was principally responsible for the ANU PBS, a version of the PBS batch system which notably supported pre-emption by the suspend/resume mechanism. This allowed large and urgent jobs to start at the expense of smaller and less urgent jobs, by suspending the latter: when the large and urgent were done, the smaller and less urgent resumed. (The ERS Schedular on the NEC SX systems had similar capabilities, but the HPCCC used the checkpoint/restart capability fro preemption.) The ANU PBS system provided excellent responsiveness and high utilisation, since there was less need to drain nodes to allow large jobs to have enough resources available to start. Utilisation on the systems prior to raijin was more than 90%. With the Fujitsu system, NCI made the decision to drop use of the ANU PBS, and relied on the commercial product PBS Pro, and never again brought suspend/resume into production. Utilisation thus dropped.
Multiple StorageTek tape drives and libraries
I was responsible for the decision to support the JSF to acquire StorageTek cartridge tape drives in 1991, which led to DMF being enabled. I championed the acquisition of the first Automated Tape Library in 1993 using the Development Fund. I later calculated that the increased utilisation of the system paid for the tape library in about a year. Subsequently, many generations of tape drives and media were acquired, as the technology marched onwards. In both 1997 and 2003-2004, CSIRO purchased an additional tape library at new sites to allow the transition from the old sites to be accomplished over weekends. See Sidebar 7. I made at least one mistake in these upgrades. I arranged to order 4 tape drives to attach to one of the Crays, but found afterwards that the Cray had only one channel. Fortunately, STK staff helped me find an ESCON Director which was able to do the fibre channel multiplexing.
The Pawsey magnus and storage systems (2010-2014)
I was involved in the initial preparations for the acquisition of the supercomputer and storage for what became the Pawsey Supercomputing Centre from 2010. I was seconded part-time to Pawsey from September 2011, having to relinquish an earlier secondment to RDSI. I acted as HPC Architect for a period when Guy Robinson was taken ill suddenly, and then acted again as HPC Architect after his departure to oversee acceptance testing.
The CSIRO cluster systems
CSIRO HPSC decided to acquire a cluster system in 2004, to enable it to offer a service on such a system and allow researchers to concentrate on research rather than on systems administration. At the same time, CSIRO Marine and Atmospheric Research had joined the Bluelink project with the Bureau of Meteorology and the Royal Australian Navy to develop, amongst other projects, a forecast system able to be targetted to areas of interest (ROAM). CSIRO HPSC undertook to acquire a prototype cluster for this application, and arranged to house it in the Bureau’s Central Computing Facility. Tenders were let for both systems, and I had to push back against a desire to specify explicitly the hardware instead of asking the vendors to deliver the best performance on a range of applications.
This was done, and IBM won the contract for clusters which became burnet (for general use) and nelson (for the ROAM development). IBM’s response included two architectures, and we chose the blade one. However, the benchmarks had been run on the other architecture, and did not perform as well on the blade architecture (because of the reduced interconnect between nodes), and so IBM had to supply extra blades to meet the targets. There are two lessons.
9. RFQs should specify the desired applications and their performance rather than explicit hardware.
10. Acceptance testing to targets is important.
CSIRO HPSC managed the replacement of the nelson cluster by a production cluster called salacia for the ROAM application in about 2007. In 2013, another replacement was needed, and the Defence Material Organisation tasked CSIRO ASC to carry out the procurement and installation.
CSIRO Data Store hosts, software and disc storage, MAID
From 1997, the Data Store was considered as a separate facility to the supercomputers. At the end of 2003, as the move of the Bureau and the HPCCC from 150 Lonsdale Street Melbourne to 700 Collins Street Docklands, CSIRO issued an RFQ for a replacement system. SGI tendered DMF (as it had inherited the rights when it acquired Cray Research, and retained the rights when it sold Cray), NEC and Cray. SGI won the evaluation, principally because the licence fees were not based solely on volume stored, and were less than the media costs – this became very important over subsequent years as the demand for storage grew. SGI tendered a system based on MIPS and IRIX, but CSIRO chose to adopt the recent port to Linux, as this was seen as the way of the future. DMF worked on the Altix Itanium and later Intel processor platforms. The biggest issue was the unreliability of the NUMA systems memory management. Various disc upgrades were undertaken, to cope with the growing demand. At some stage around 2008, CSIRO IM&T had arranged a panel contract for the supply of all disc storage, which made it difficult to enhance the storage on the SGI hosts. In 2011, CSIRO acquired a MAID – Massive Array of Idle Discs. This provided storage intermediate in performance and cost between enterprise fibre-channel high speed disc and tape. The discs in the MAID were treated like tape volumes, and were switched off when not in use, but could be brought back to life in under 20 seconds. The MAID was a successful ‘green’ device, saving power compared with always-spinning disc.
11. Panel contracts are useful for reducing the work involved in full tenders, but should not be mandatory.
12. The full costs over the life-time of a system need to be considered, especially any costs based on the capacity used.
Bureau Cray system (Aurora) (2013-2014)
I was again involved in the Bureau’s Supercomputer RFT, which led to the acquisition of the Cray XC40 system (aurora).
The NCI gadi system
In March 2018 I was appointed to a Consultation Group for the tender for the replacement of raijin. It appears the group never met.
Resource Allocation and Scheduling
Resource allocation for shared resources (such as corporate HPC systems) has been a thorny issue for decades. I’ve written above about the charging regime in the Csironet era, which largely contributed to its downfall. I’ve written above about share schemes and the fair share concept which arose in the 1990s. Here’s a paper from 1991 (presented to the Australian Supercomputer Conference): Resource Allocation on Supercomputers.
Here is a talk given in 2017 on Resource Allocation. The talk covers allocation of compute and storage resources, with examples of good and bad. I’ve mis-quoted Tennyson’s “The Brook” with
“Flops may come and flops may go, But bytes go on for ever.”
John Mashey once wrote: “Disks are binary devices: new or full”
Scheduling of compute loads was and maybe still is an important issue. I’ve written about some of the issues in the context of the CSF and HPCCC. The larger the system, and the more parties involved, the more important scheduling becomes: it is part of the process for ensuring that the resources are delivered in accordance with whatever policies are laid down. The workload benchmark from 2003 was an important tool in getting a good result for the 2003 HPCCC procurement. Only one vendor, NEC, was able to demonstrate compliance with the workload benchmark, which attempted to simulate a system running as much background work as possible while still responding rapidly to urgent tasks such as running operational weather forecast models. The scheduler was important for the CSF Cray reaching an average of 98.5% CPU utilisation.
It is disappointing to see that some HPC centres still show large amounts of idle time, and still have large areas of storage under-utilised.
Colleagues
It has been a privilege to work with many colleagues who have given me strong support in my career. I will single out Alan Plumb who gave me a start in my support role, Jorgen Frederiksen for his confidence in me and supporting me, Brian Tucker for employing me and giving me opportunities, Len Makin (as as a wonderful deputy for about 15 years), Jeroen van den Muyzenberg as systems administrator, and Peter Edwards as a dedicated systems administrator of CSIRO’s Data Store for about 18 years, and a great supporter for the DMF User Group. Gareth Williams and Tim Ho in more recent times have been part of my story.
When I first arrived at DIT Carlton from May 1990, I was amazed at the level of support given to me by the administrative staff – led by Sue Wilson, but including Marita O’Dowd, Teresa Curcio, and later Jim Taylor. Teresa went on to support CSIRO HPSC, ASC, and IMT SC for many years as the sole administrator.
Personal Reflections
My university education and early career became captivated by the power and potential of computation. I was inspired by the possibilities of computation to model the real world, and to the benefits from this, for example in weather forecasting, as I envisaged in 1962 (see above). Computation enabled scientists to gain greater understanding of the world around us.
My career as a research scientist never eventuated, but I found my niche at Aspendale in doing the programming in support of the scientists, such as Alan Plumb, Peter Baines, Peter Webster and Jorgen Frederiksen.
Having used to the fullest extent the computational facilities available, I became motivated to improve the services in the service of science, becoming Computing Group Leader at Aspendale, and then moving into corporate CSIRO HPC from 1990. It was not just the facilities, but the policy framework that I wanted to provide, so that users could get the maximum benefit – this meant policies that allowed open access and promoted high utilisation of the limited CPU resources available at the time – 98.5% on the CSF Cray Y-MP. Providing good storage facilities became a major focus for me, and so I jumped at the opportunity to initiate the DMF service on cherax, which provided virtually ‘infinite’ capacity for users to store data from 14 November 1991.
There is a Christmas carol entitled “A Boy was Born” set to music by Benjamin Britten. It contains the line: “He let himself a servant be”, and that became my guide in the service to science.
Clive James wrote something like: “if you can’t be an artist, then at least serve the arts”. I resonated with this for the science and scientists I worked with, seeking to provide the best environment – processors, storage, software, services and support.
I have been interested in the intersection of science and faith for many years, and have been helped in this journey by several sources. I read “The Mind of God” by Paul Davies, who gives an overview of the universe we live in, the development of life and the complexity which leads to human beings, who, he remarks are the only conscious beings capable of understanding this universe. He concludes with the lines:
“I cannot believe that our existence in this universe is a mere quirk of fate, an accident of history, an incidental blip in the great cosmic drama. Our involvement is too intimate. The physical species Homo may count for nothing, but the existence of mind in some organism on some planet in the universe is surely a fact of fundamental significance. Through conscious beings the universe has generated self-awareness. This can be no trivial detail, no minor byproduct of mindless, purposeless forces. We are truly meant to be here”.
He and others write about the remarkable world we live in, in which everything is just right for the development of carbon, life, etc.
In 2018, Professor Stephen Fletcher was visiting CSIRO Clayton from Loughborough University, and gave a series of 8 lectures entitled: “Life, The Universe and Everything”. I was able to attend some of these. In the last lecture, he addressed Philosophical Questions about science, knowledge, truth, the big bang, etc. “Both space and time came into existence at the start of the Big Bang”. “After the Big Bang… A very weird thing is…the apparent design of the Universe to allow the evolution of life” “Some Physical Constants are very ‘Finely-tuned’ for Life to Evolve..”.
He concluded that, on the basis of the special nature of our universe, that there were four possible explanations. These were:
- A Divine Creator exists
- We are Living in a Computer Simulation
- Our Universe is just one member of a multitude of Universes that together comprise a “Multiverse”.
- The Inevitability Hypothesis – A future physical theory (a “Theory of Everything”) might still be developed that has no free parameters.