Sidebar 7: Data-intensive computing, cherax, ruby, DMF, the Scientific Computing Data Store, tape libraries – a retrospective
Sidebar 7:
Data-intensive computing, cherax, ruby, HSM, DMF, the Scientific Computing Data Store, tape libraries – a retrospective
Last updated: 23 Jun 2025 to add cross-reference to more information under Rob Bell’s personal computing history.
Updated19 Jun to 14 Jull 2025 to document the transition to ScoutAM.
Updated: 19 Feb 2024: updated a link.
11 Oct 2023: Added information on and pictures of tape libraries.
9 Aug 2023: Added links to SC manuals on the Data Store, and a history page.
Added link to Why HSM? presentation.
Added and updated 30-year anniversary note. Added note about DMF Users Group. Added note about STK library retirement.
Robert C. Bell
With the commencement of service of CSIRO’s first Cray Y-MP (“cherax”) in March 1990, the installation of StorageTek cartridge tape drives in mid-1991, and the start of Cray’s Data Migration Facility on 14th November 1991, a unique partnership developed – a high-performance compute service and a large-scale data repository as closely coupled as possible. With the start of automation of tape mounting in June 1993 with the installation of a StorageTek Automated Tape Library, the foundation was set for a platform to support large-scale computing on large-scale data (large-scale for the time).
Users were freed from the need to deal with mountable media (tapes, floppy discs, diskettes, CDs), and the users’ data was preserved safely and carried forward through many generations of tape technology, all done transparently behind the users’ backs on their behalf – 13 generations of drive/media so far, going from 240 Mbyte to 20 Tbyte (and more with compression) on a single tape cartridge. There were a succession of hosts – three Cray vector systems (cheraxes running UNICOS), 4 SGI hosts (3 cheraxes and ruby running Linux), and now dedicated servers.
Users had a virtually infinite storage capacity – though at times very little of it was available on-line – the Hierarchical Storage Management (HSM) would automatically recall data from lower levels when it was required, or users could issue a command to recall sets of data in batches. It was somewhat difficult for new users to get used to (to them, DMF stood for “Don’t Migrate my Files”), but experienced users valued the ability to have large holdings of data in one place.
Unlike many sites, the Data Store was directly accessible as the /home filesystem on the hosts. This overcame the problem of managing a large shared filesystem, and DMF took care of the data as it filled by copying data to lower cost media, and removing the data (though not the metadata) from the on-line storage. Other sites (such as NCI, Pawsey and the main US supercomputer centres) ran their mass storage as separate systems, with users having to explicitly send data from the compute to the storage servers, and recall explicitly: users then had a minimum of two areas to manage, rather than just one.
One of the main users ran atmospheric models on various HPC platforms in Australia, but always copied data back to the Data Store for safe-keeping, and to enable analysis to be carried out in one place.
The Data Store continues after the de-commissioning of ruby on 30th April 2021, as the filesystem is available (via NFS) on the Scientific Computing cluster systems. There is no general user-accessible host with the Data Store as the home filesystem.
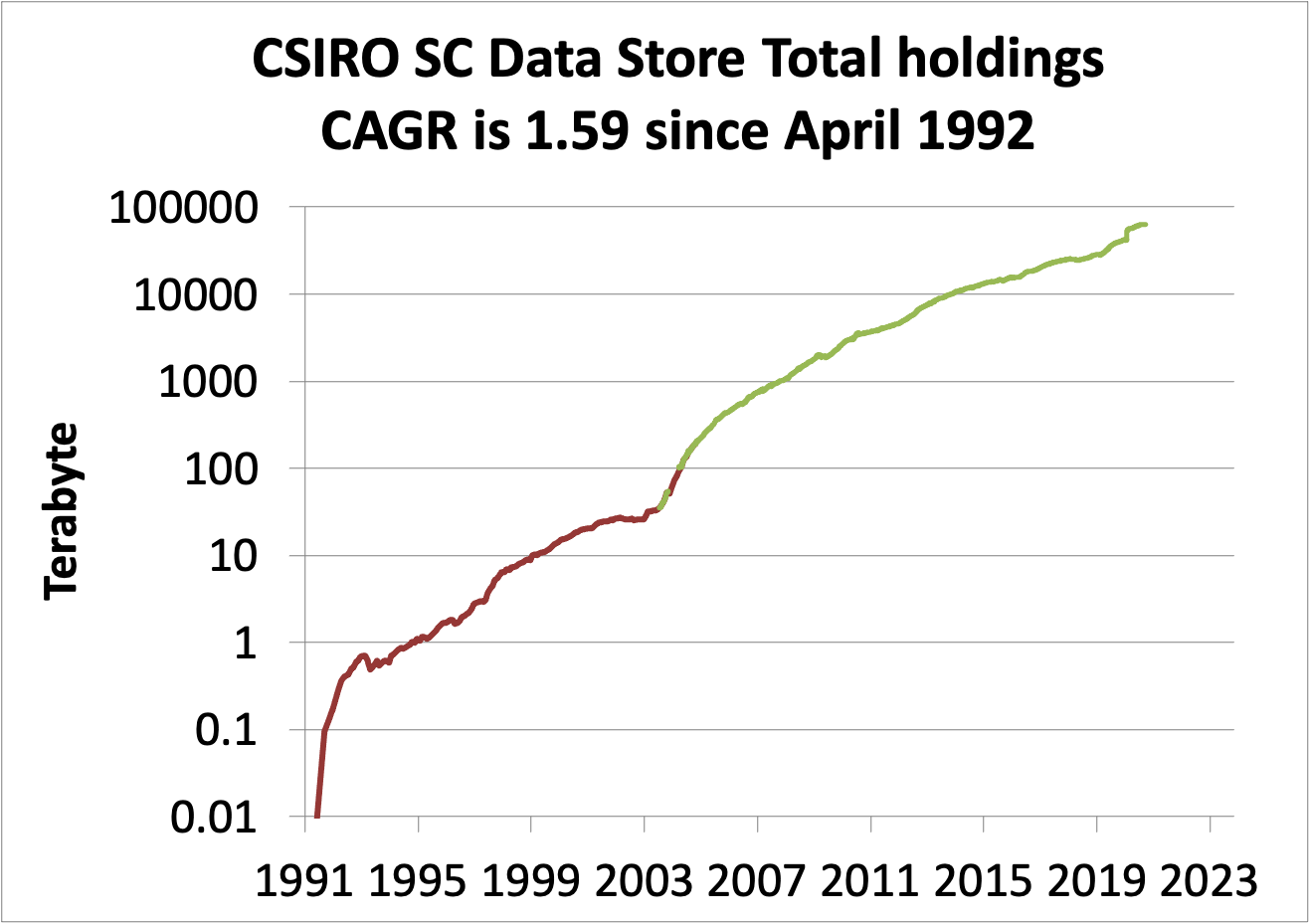
Below is a graph showing the total holdings in the Data store since 1992. The compound annual growth rate over that period was 1.59 – meaning that the amount stored increased by 59% each year.
The Data Store depended heavily on the strong support from the staff and technology of the vendors (principally Cray Research, SGI, StorageTek/Sun/Oracle, and lately IBM, HPE and Spectralogic), and the superb support by the systems staff – principally Peter Edwards, but also Ken Ho Le, Virginia Norling, Jeroen van den Muyzenberg and Igor Zupanovic. Peter Edwards retired on 17th May 2024, and Ajaya Sharma became the systems administrator.
Thanks Team!
In 2009, Peter Edwards and I formed a DMF User Group, to allow sites running DMF to share information. See DMF Users Group.
Rob.
P.S. Note that CSIRO developed its own operating system (DAD) and own HSM (the document region) in the late 1960s, using drums, disc and tape (manually mounted), with automatic recall of files, and integration with the job scheduler so that jobs blocked until the required files had been recalled! See Sidebar 1.
P.P.S. Here’s a link to talk given in 2012 entitled, Why HSM?
Thirty Year Anniversary of the CSIRO Scientific Computing Data Store CSIRO and DMF
On 14 November 1991, the Data Migration Facility (DMF) was brought into operation on the CSIRO home file system on the Joint Supercomputing Facility Cray Y-MP (cherax).
This became known as the CSIRO Scientific Computing Data Store, and will be thirty years old on 14th November 2021, being managed by DMF over all those years. The above provides some of the history, and more is provided in the Personal Computing History sidebar. The Data Store became an important part of the services to science, and one that I attempted to champion for the benefit of the users.
It has grown from a 1 gigabyte disc storage in 1990-1991 to over 62 petabyte – a factor of 62 million.
Although it started in its current form in 1991, it contained files from the start of the cherax service in March 1990, and I (and possibly other users) had carried files forward from older systems, e.g. Csironet. I can identify files in the Data Store dating back to the 1970s and 1960s.
From its inception for about 20 years, the Data Store provided storage for the bulk of CSIRO’s climate model output data, and the cheraxes were the primary data analysis platform.
The physical layer of storage is the sine qua non of data preservation, and the Data Store has provided this.
The Data Migration Facility (DMF) was originally developed by Cray Research for UNICOS. It passed into the hands of SGI when it acquired Cray Research. SGI held on to DMF when it sold Cray Research, and ported DMF to IRIX and Linux. Latterly, HPE acquired both Cray Inc and SGI, and renamed DMF as the Data Management Framework.
CSIRO SC Information
There is a System Guide to the SC Data Store here (CSIRO only). This contains a link to a history page (CSIRO only).
Plaque
Here’s a picture of a plaque presented to CSIRO in 2011.
Tape Libraries
Chapter 3 recorded that Csironet acquired a Calcomp/Braegan Automated Tape library in the early 1980s. This used 9-track STK round tape drives, with tape capacities around 160 Mbyte.
The CSIRO Supercomputing Facility acquired a StorageTek ACS4400 tape library which was installed at the University of Melbourne in June 1993. It and subsequent STK libraries could hold about 6000 tape cartridges.
When CSIRO joined the Bureau of Meteorology in the HPCCC, CSIRO acquired a similar STK Powderhorn tape library which was installed at 150 Lonsdale Street Melbourne.
When the HPCCC moved with the Bureau from 150 Lonsdale St to 700 Collins St Docklands, a shell game was played with another Powderhorn being installed at 700 Collins St, and the Bureau and CSIRO staging the transitions until there were two Powerhorns at Docklands, and one old one from 150 Lonsdale Street being traded in.



In 2008, CSIRO acquired an STK/Sun SL8500, to allow support for newer tape drives, and the Powderhorn was decommissioned.


In 2015, the CSIRO HSM was moved from Docklands to Canberra, with backup facilities at Clayton. CSIRO acquired IBM TS4500 tape libraries:




and then Spectralogic Tnfinity libraries.



Each type of library has its own advantages and disadvantages. Much discussion centred around access times. The Powderhorn libraries had access times of only a few seconds to any tape cartridge, but could deal with only one retrieval at a time. The SL8500 libraries had four levels with one or two robots per level, providing multi-tasking, but cartridges and drives needed careful placement to avoid too many demands on the elevators that moved cartridges between levels.
The IBM libraries have a unique feature of being able to store two cartridges in some deep slots, but of course access to the ‘hidden’ cartridge is slower.
The Spectralogic libraries store tapes in small trays (up to 10 cartridges per tray): the robot retrieves a tray, and then selects the desired tape from the tray.
Optimising the layout was difficult for the later libraries. This is on top of the problem of optimising multiple retrievals from a modern tape which is written in serpentine fashion.
See Wikipedia Magnetic tape data storage
See also further information in the Rob Bell Personal computing history pages here
Transition – 2025
In 2025, CSIRO selected the ScoutAM product to replace DMF. (ScoutAM is derived from SAM-FS, a well known archive product. See here for more information).
Here is the announcement to users.
Scheduled Outage – DMF/Datastore Replacement
Start: Friday, 20 June 2025 12:00 AEST
End: Monday, 30 June 2025 09:00 AEST
Services Affected: During this period, Datastore will be unavailable.
Reason: The Data Migration Facility(DMF) service that underpins Datastore is end-of-life and is being replaced.
Further Information:
IMT Scientific Computing is replacing the end-of-life DMF with a new system, Versity ScoutAM. ScoutAM provides a database migration only pathway from DMF, which means that the data remains in place and no user data migration is required.
Please note that there are a number of changes in the configuration and behaviour of the system as follows:
-
- The default online data quota is changing, please see DMF to ScoutAM for details
- Migration of files to tape is automatic according to policies, there is no equivalent dmput command
- The command line tools used to manage files under ScoutAM are different from DMF. Primarily, instead of having multiple commands (e.g. dmget, dmput), ScoutAM uses one command (samnfs) with subcommands (e.g. samnfs ls *). For information on the new commands, please visit ScoutAM .
For more information please visit the ScoutAM page, the DMF to ScoutAM migration page or contact IMT Scientific Computing via [email protected]. Please keep an eye on the migration page as it will be regularly updated.
Did you know you can get details of system and service outages online? See IMT Outages and Service Advice
Contact: For more information please contact IMT Scientific Computing via [email protected]
In early July, the transition was completed, and users continued to have access to all their files in the SC Data Store as a mounted filesystem.
